『n8n×ChatGPT×Gemini』文章の「質」を極める!異なるAIの強みを掛け合わせた自動リライト・推敲システム
自動化
2026.01.28


n8nで請求書処理を完全自動化しませんか?Gmailに届く請求書PDFをAIが自動で読み取り、内容をスプレッドシートに記録する、プロが組んだ実用的なワークフローを徹底解説しました。各ノードの役割や設計思想まで深く理解できる、一歩進んだ自動化ガイドです。

・最新の生成AI導入からシステム開発まで幅広く対応
・企業の生産性向上を強力にバックアップします
企業活動において、請求書の処理は避けて通れない定型業務です。しかし、その手作業による工数は決して少なくありません。この課題を解決する強力なツールが、ノーコード自動化プラットフォーム「n8n」です。
n8nを用いれば請求書処理の自動化は可能ですが、実用性と将来のメンテナンス性まで考慮した「優れたワークフロー」を構築するには、一定の設計思想が求められます。
幸いなことに、n8nのエキスパートによって公開されている、まさに「お手本」と呼ぶべきワークフローが存在します。本記事ではその優れた作例を元に、各ノードがなぜその役割を担い、なぜその順序で配置されているのかという設計思想を、詳細に分析・解説します。
使用するワークフロー:Invoices from Gmail to Drive and Google Sheets
このワークフローは、単なる処理の連続ではなく、大きく4つの明確な役割を持つフェーズで構成されています。この構造を理解することが、全体の設計思想を把握する上で極めて重要です。
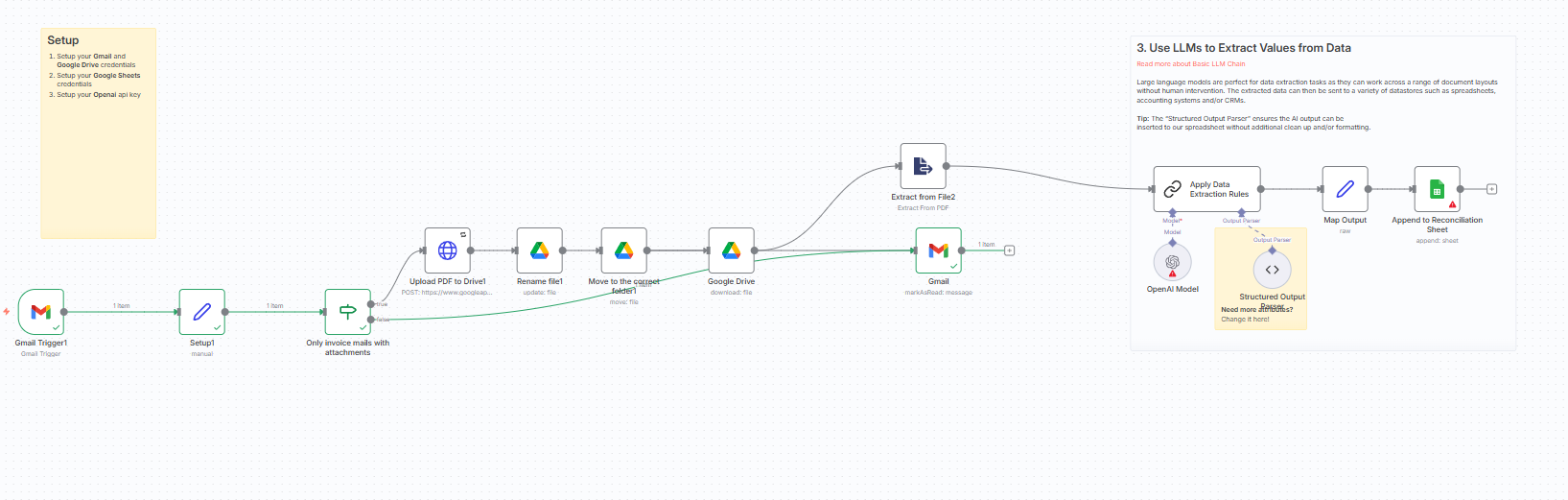
フェーズ1:検出と準備 (Detection & Preparation)
・Gmailを監視し、処理対象となるメールを特定。後続の処理で利用する設定値を初期化します。
フェーズ2:堅牢なファイル管理 (Robust File Management)
・添付PDFをGoogle Driveへ安全にアップロードし、定義された命名規則に従ってリネーム、そして指定フォルダへ整理・格納します。
フェーズ3:AIによるデータ抽出 (AI-Powered Data Extraction)
・整理されたPDFをAIが解析可能な形式に変換し、必要な情報を構造化データとして抽出します。
フェーズ4:データの整形と記録 (Data Formatting & Archiving)
・抽出されたデータと関連情報を最終的に整形し、Googleスプレッドシートへ永続的な記録として保存します。
ワークフローの最初のフェーズは、自動化プロセスの起点となる部分です。ここでは、処理対象となるメールを正確に捕捉し、後続の処理を円滑に進めるための下準備を行います。確実なトリガーとメンテナンス性の高い設定が、このフェーズの鍵となります。
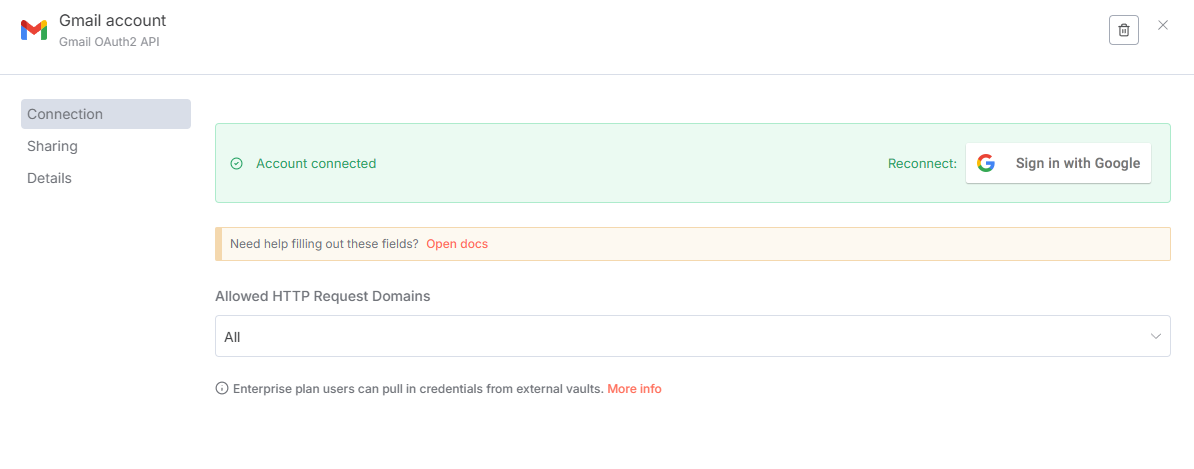
全自動化プロセスの起点です。Gmail APIを介して定期的にメールボックスを監視し、「未読の受信トレイに新規メールが到着した」というイベントを検知した際に、後続のノードへメールデータを渡し、ワークフロー全体を起動します。連携する予定のGoogleアカウントでログインすることで設定が完了します。
このノードは、ワークフロー全体のメンテナンス性を飛躍的に向上させるための、極めて高度な設計思想の現れです。PDFの保存先フォルダIDなど、将来的に変更される可能性のある値を、ワークフローの冒頭で変数として定義しています。
保存先フォルダの変更が必要になった際、ワークフロー内の複数のノードを修正するのではなく、この単一のSetノードの値を変更するだけで対応が完了します。これは「設定の外部化」と呼ばれるベストプラクティスであり、ワークフローの保守性を担保する上で不可欠な要素です。
Gmail Triggerが検知した全てのメールを処理対象とするのではなく、「添付ファイルが存在するメール」のみを後続の処理へ進めるための条件分岐(フィルター)です。添付ファイルが存在しない場合は、この時点で処理を終了させ、不要なリソース消費を防ぎます。
メールから取得したPDFファイルを、ただ保存するだけでは不十分です。このフェーズでは、ファイルを安全にアップロードし、後から人間が管理しやすいように命名と整理を行います。一連の丁寧なファイル操作が、自動化システムの信頼性を高めます。
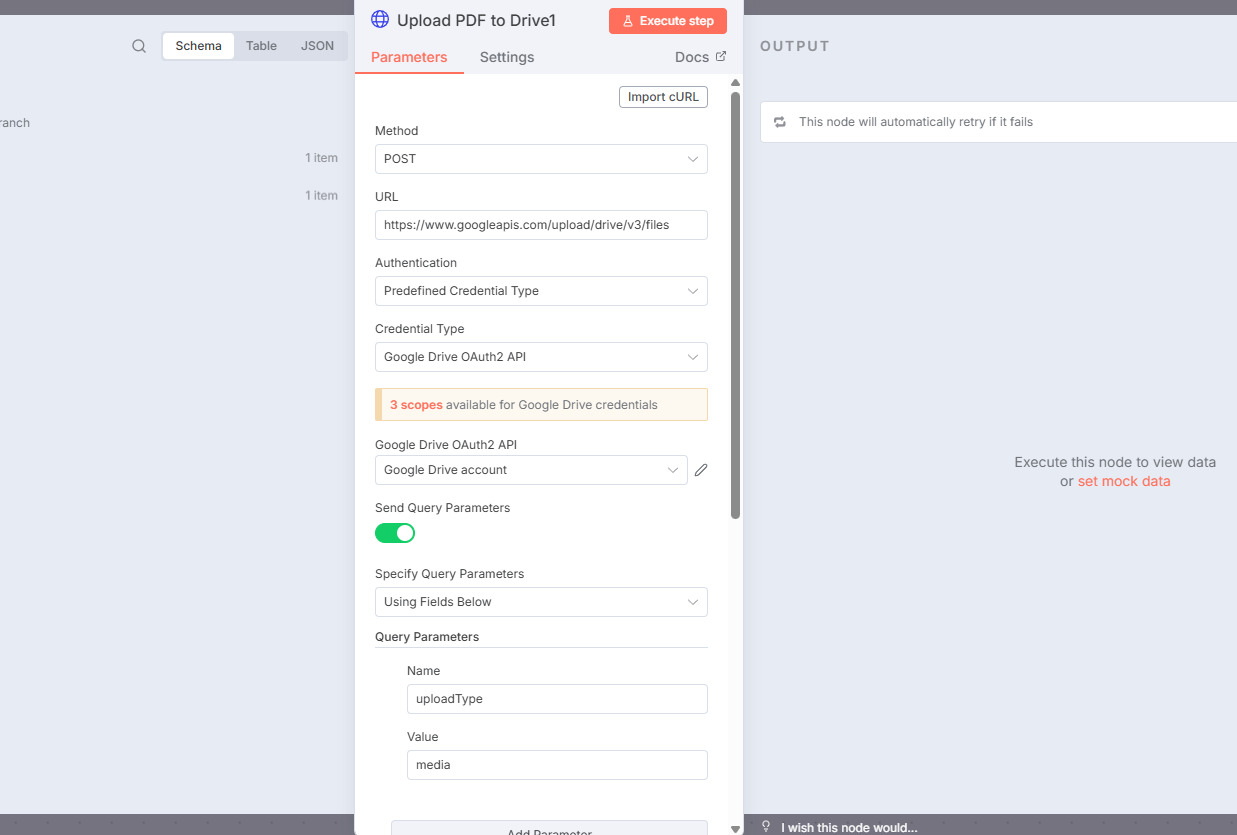
Gmailから受け取ったPDFのバイナリデータを、Google Drive APIのエンドポイントに直接POSTリクエストとして送信し、ファイルをアップロードします。
標準の「Google Driveノード」でもアップロードは可能ですが、より低レベルなAPI操作を可能にする「HTTP Requestノード」を意図的に採用しています。これにより、APIからのレスポンス(アップロードされたファイルのIDを含む)を直接的かつ確実に取得できます。
このファイルIDは、後続のリネームや移動処理に必須であるため、この確実性がワークフロー全体の安定性を支えています。
アップロード直後のファイルに対し、「受信日_送信者名_件名.pdf」といった一貫性のある命名規則を適用し、ファイル名を変更します。
ファイル名の標準化は、後の手動検索時における検索性(Discoverability)を劇的に向上させます。いつ、誰から、何の請求書であるかがファイル名から即座に判断できるため、管理性が大幅に向上します。
命名が完了したファイルを、Google Driveのルートディレクトリから、フェーズ1のSetノードで定義した専用の保管フォルダへ移動させます。これにより、ファイルがDrive内で散在することを防ぎ、体系的な文書管理を実現します。
このフェーズは、ワークフローのインテリジェンスを担う心臓部です。整理されたPDFファイルから、AI(大規模言語モデル)の能力を活用して、非構造化データである請求書の内容を、機械が扱える構造化データへと変換します。
この2つのノードは一連の処理として機能します。まずGoogle Driveから整理済みのPDFをn8nに再度ダウンロードし、次に「Extract from Fileノード」がPDFからプレーンテキスト情報を抽出します。
大規模言語モデル(LLM)はPDFのレイアウトを直接解釈できないため、このテキスト化という「データ前処理」がAIによる解析の前提条件となります。
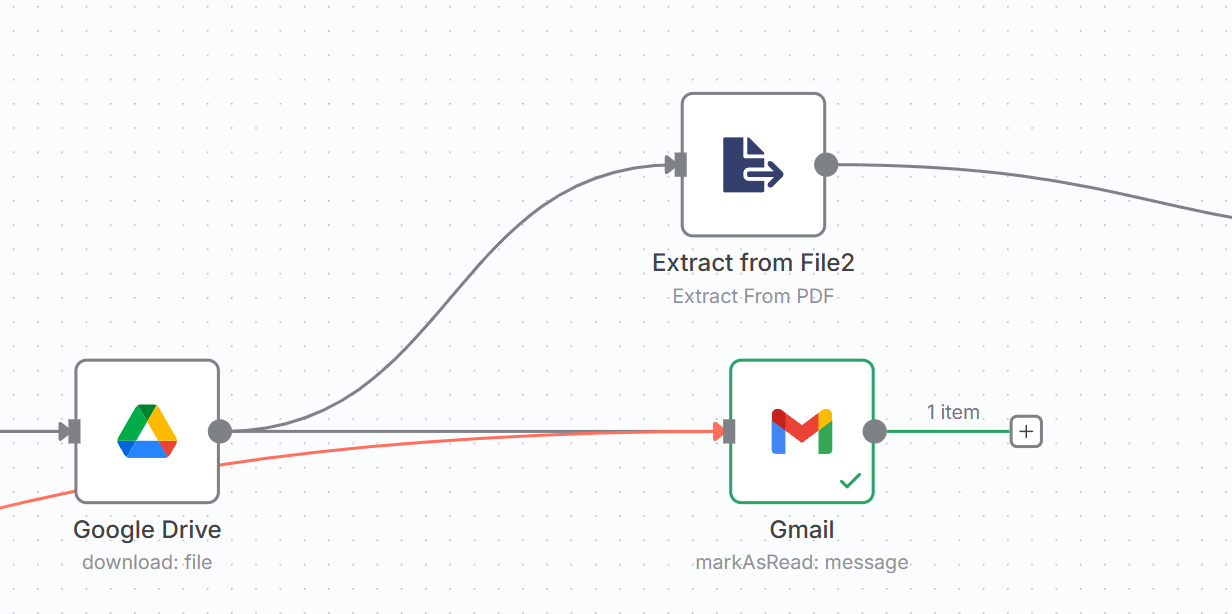
ワークフローの中核をなす情報抽出エンジンです。前処理されたテキストデータを、定義されたプロンプト(指示文)と共にOpenAIのGPT-4oモデルに送信します。
AIはプロンプトに従い、テキスト内から「請求日」「金額」といった指定項目を識別し、機械判読可能な構造化データ(JSON形式)として返却します。
ここでは事前に用意しておいたOpenAI APIの設定が必要となります。
自動化の最終段階として、AIが抽出したデータをそのまま記録するのではなく、必要な情報を付加して整形し、永続的なデータとして保存します。これにより、後から活用しやすい、整理されたデータ台帳が完成します。
AIが抽出したデータと、それ以前のノードが保持する情報(例: Google Driveノードが持つファイル名)を最終的に統合し、Googleスプレッドシートの列構成に合致するようデータマッピングを行います。
AIは請求書の内容しか抽出できません。ファイル名のようなメタデータは、他のノードの出力に含まれています。このように、異なるコンポーネントからの出力を集約し、最終的なレコードを形成するのがこのノードの役割です。
完全に整形されたデータを、Googleスプレッドシートに新しい行として追記します。これにより、処理された請求書の情報が時系列で一覧化された台帳が自動的に生成され、全自動化プロセスが完了します。
これまで毎月、多くの時間を費やしてきた請求書処理が、24時間365日働く自動化システムに置き換わると、あなたの働き方はどう変わるでしょうか。このワークフローは単なる技術的な解決策に留まらず、あなたの貴重な時間を創出するための仕組みとして機能します。
単純なデータ入力作業から解放されることで、より分析的、戦略的な、付加価値の高い業務に集中できるようになります。あるいは、定時で仕事を終え、プライベートな時間を充実させることも可能になるでしょう。
ぜひ、n8nのキャンバスを開き、本記事で解説したワークフローを参考に、まずはあなた自身の業務の一部を自動化することから始めてみてください。請求書処理の自動化は、業務改革の記念すべき第一歩となるはずです。
株式会社TWOSTONE&Sonsグループでは
60,000人を超える
人材にご登録いただいており、
ITコンサルタント、エンジニア、マーケターを中心に幅広いご支援が可能です。
豊富な人材データベースと創業から培ってきた豊富な実績で貴社のIT/DX関連の課題を解決いたします。



幅広い支援が可能ですので、
ぜひお気軽にご相談ください!

