『n8n×ChatGPT×Gemini』文章の「質」を極める!異なるAIの強みを掛け合わせた自動リライト・推敲システム
自動化
2026.01.28

.png)
Podcast情報収集を効率化!ノーコードツールn8nとAIで、音声を自動要約・通知するワークフローの作り方を解説します。RSS取得からOpenAI設定、Slack通知までの全5ステップを網羅。エラー回避やコスト管理のコツも解説。初心者でも自分だけの収集システムが構築しやすくなります。

・最新の生成AI導入からシステム開発まで幅広く対応
・企業の生産性向上を強力にバックアップします
音声コンテンツは専門的な情報を得る手段の一つとして利用されますが、長尺のPodcastを最初から最後まで聴くための時間を確保するのは難しい場合があります。限られた時間の中で要点を把握したいと考える読者に向け、効率的な情報取得の仕組みが求められています。
この課題に対し、ワークフロー自動化ツール「n8n」と音声認識・文章生成技術を組み合わせる方法が活用されています。n8nはローコードで処理を構築できるため、外部サービスと連携して音声の文字起こしや要点抽出を行うフローを設定できます。高い専門知識がなくても、一定の範囲で自動化環境を整えられる点が特徴です。
本記事では、n8nを用いてPodcastの音声取得から要約までを自動化する流れと、運用時に配慮するポイントを段階的に整理します。作業負担の軽減や情報整理の効率向上を目指したい方はぜひ参考にしてください。
※画像は全てイメージです。
Podcastの音声データを自動で文字化し、要約を生成する仕組みを導入すると、作業時間の軽減だけでなく、情報整理のしやすさや内容確認の利便性が向上しやすくなります。ここでは、活用シーンに基づく主な利点について解説します。
音声コンテンツは「流し読み」ができず、必要な情報を探すのに時間がかかるのが課題です。n8nを用いた自動要約は、この非効率性の軽減が期待できます。
自動化により、エピソードの概要や重要ポイントが箇条書きで整理され自動的に手元に届くため、全体像を短時間でつかみ、興味のあるテーマかどうかを容易に判断できます。
これにより、優先して聴取すべきエピソードの選別が容易になり、限られた時間を有効活用できるでしょう。また、移動中や作業の合間など、音声を聞くことが難しい環境でも、テキストであればすぐに内容を確認できる利便性も大きなメリットです。
音声コンテンツの課題として、全文検索が難しく、後に特定の話題を探すときに手間を要する点があります。要約データや文字起こしを保管することで、情報の再利用性を向上させることが可能です。
n8nのワークフローを通じ、Google SheetsやNotionなどのデータベースに要約結果を自動保存する仕組みを整えると、過去の放送内容をキーワードで検索できるようになります。必要な情報をスムーズに確認できるでしょう。
文字起こしデータと要約をセットで保存すれば、詳細な文脈を確認したいときも該当箇所へスムーズにアクセスしやすくなります。この仕組みは、音声コンテンツを自社の知識ベースとして資産化し、業務効率化の可能性を秘めていると言えるでしょう。
n8nは連携できるアプリケーションが豊富であり、出力先やフォーマットを自社の運用に合わせて柔軟にカスタマイズ可能です。例えば、チームメンバーとの情報共有を重視する場合はSlackやMicrosoft Teamsへの通知を設定し、個人の学習記録として残したい場合はGoogleスプレッドシートやSlackへの保存を選択できます。
n8nは複数の外部サービスと連携できるため、要約結果をSlackやGoogle Sheetsなどに送る構成の構築も容易です。Slackではメッセージ形式を調整できるため、概要・URL・ポイントなどをまとめて送信し、確認作業を簡単にすることも可能です。自分が見やすいフォーマットに整形された情報が、日常的に使用しているツールへプッシュ通知されることで、情報確認の習慣化がスムーズになります。
実際にワークフローを作成する前に、全体像と必要な準備物を整理しておきましょう。処理の流れや使用する外部サービスを事前に把握し、必要な認証情報を準備しておくと構築が進めやすくなります。ここでは概要と準備項目を整理します。
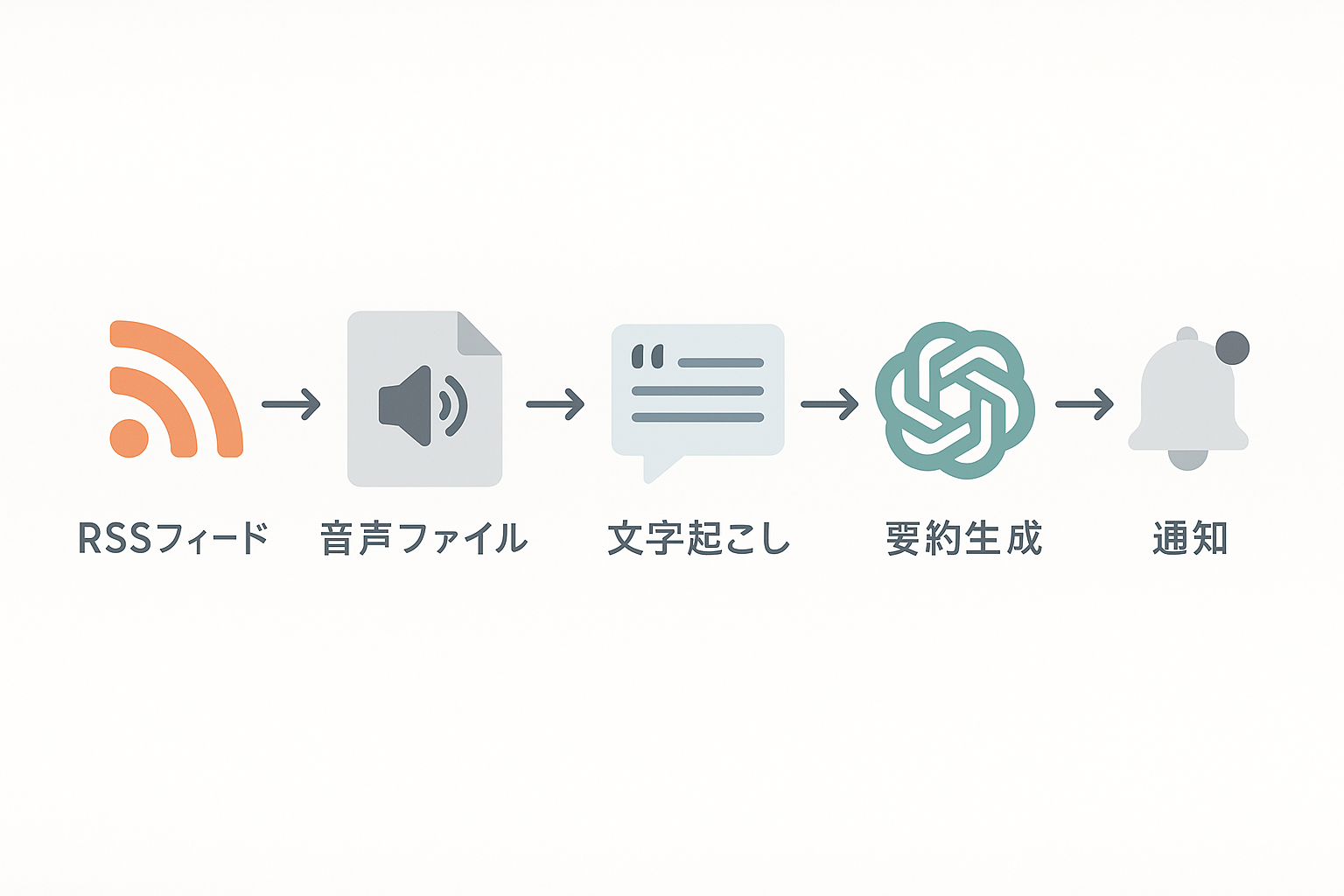
今回構築するワークフローの基本的な流れは以下のとおりです。
毎日決まった時間にワークフローを起動させます。
対象となるPodcastの更新情報を取得します。
過去に処理したエピソードを除外し、新しいエピソードのみを抽出します。
RSSに含まれる音声データのURLから、ファイルをダウンロードします。
OpenAIのSpeech-to-Text API(Whisper)を使用して、音声をテキスト化します。
文字起こしされたテキストをOpenAIのChat Modelに渡し、要約を作成します。
Slackへの通知やGoogleスプレッドシートへの記録を行います。
この一連の流れをn8n上のノードとして配置し、線でつなぐことによって自動化を実現します。特に「新着判定」と「音声処理」の部分が、このワークフローの軸となります。
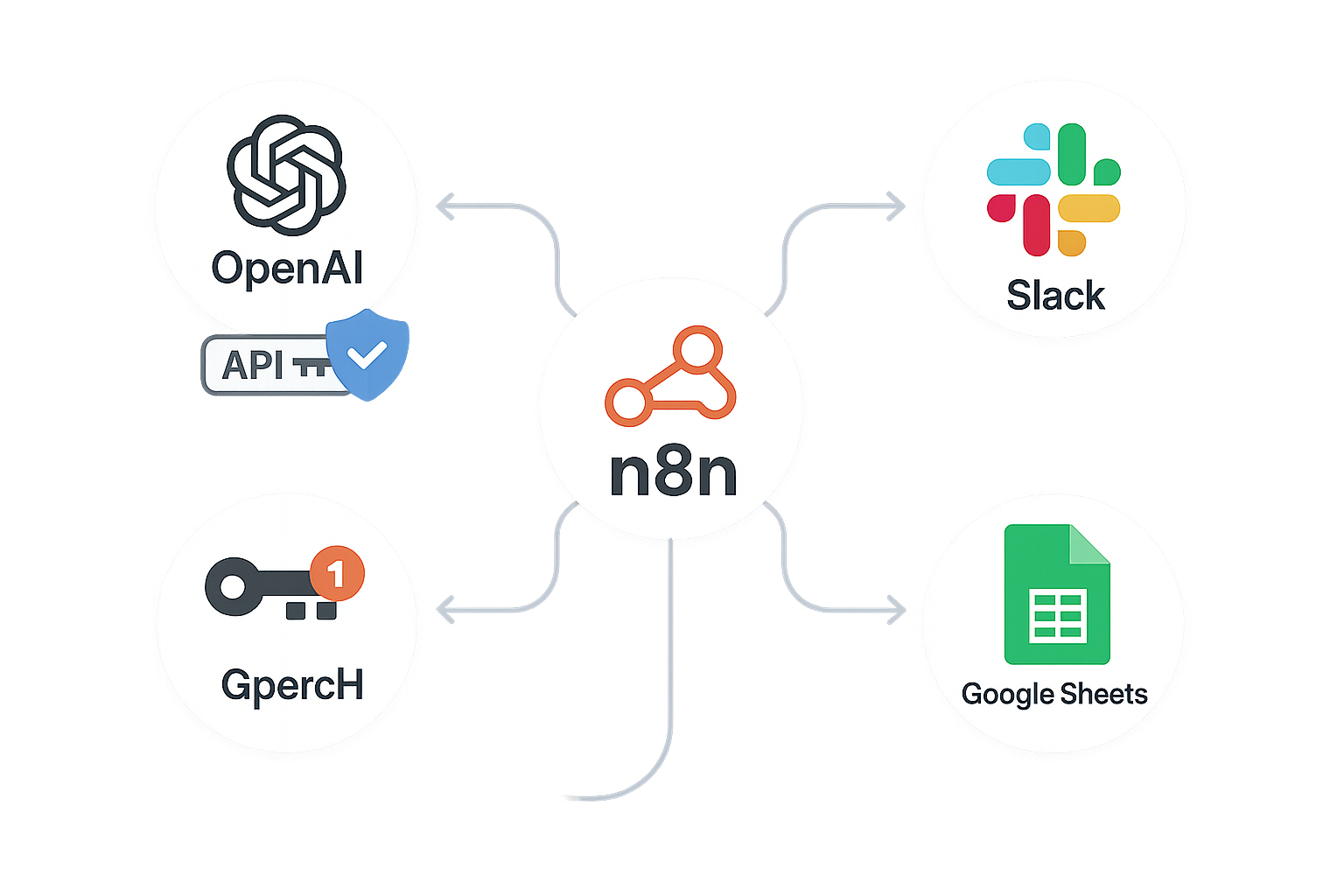
n8n自体はデータの受け渡しを行うハブのような役割を果たすため、実際の処理を行う外部サービスとのAPI連携が必要です。以下のサービスについて、アカウント登録と設定を済ませておいてください。
音声の文字起こし(Whisperモデル)と文章の要約(GPT-4oなど)に使用します。APIキーの発行と、従量課金となるためのクレジットカード登録が必要です。OpenAIのAPIキーはアカウント管理画面で発行し、n8nのCredentialに安全に保存して使用します。SlackやGoogle Sheetsを用いる場合も、各サービスで必要な認証項目を取得し、n8n側で連携設定を行います。認証情報は第三者に共有されないよう慎重に扱う必要があります。
要約結果の通知先として使用します。Slackアプリを作成し、「Incoming Webhooks」のURLを取得するか、Bot User OAuth Tokenを発行してn8nと連携させます。
要約をスプレッドシートに保存する場合は、Google Cloud Consoleでプロジェクトを作成し、Google Sheets APIを有効化する必要があります。OAuth2認証の設定を行うことで、n8nからシートへの書き込みが可能になります。
各サービスのAPIキーや認証情報は、外部に漏えいしないよう厳重に管理してください。n8nでは「Credentials」機能を使用してこれらを安全に保存し、各ワークフローから呼び出して使用する仕組みになっています。
Podcastの情報を取得するには、番組ごとの「RSSフィードURL」を確認する必要があります。ただしApple PodcastsやSpotifyではRSSが直接表示されない場合があるため、番組公式サイトのRSSアイコンを探すか、Listen Notesなどの検索サービスやRSS抽出ツールを利用してURLを調べます。配信プラットフォームによりRSSの形式は異なるため、取得後はブラウザで開き、正しく配信されているか確認しておくと安心です。
RSSを開いた際には、タイトル・公開日・音声ファイルURLなどが含まれているかを確認します。音声ファイルは<enclosure>やmedia:contentといったタグで提供される場合があるため、これらが取得できればn8nのRSS取得ノードに設定できます。正しいRSS URLを事前に把握しておくことで、後続の文字起こしや要約処理を安定して進めやすくなります。
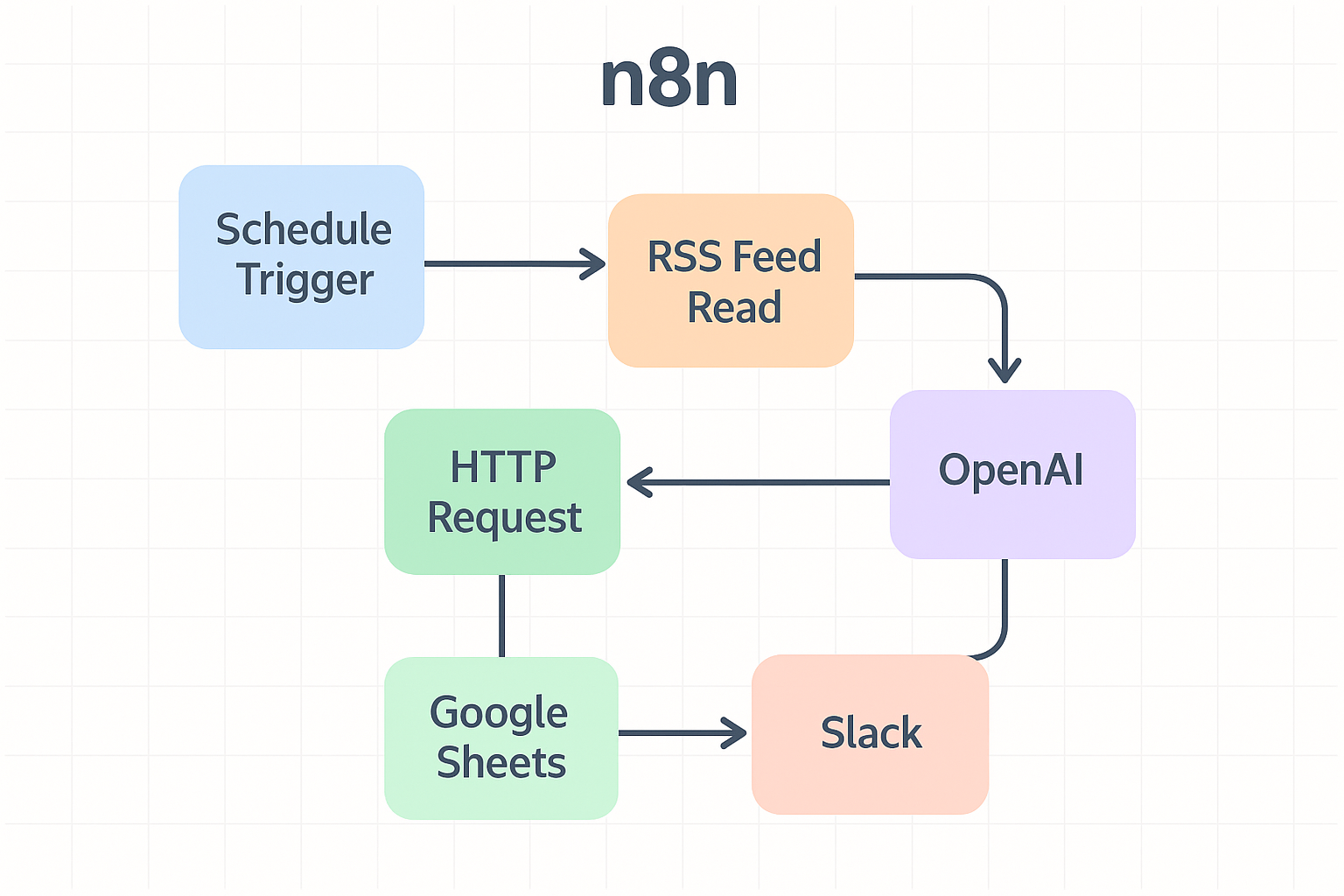
ここからは、実際にn8nの画面を操作しながらワークフローを構築する手順を解説します。複雑に見える処理も、一つずつノードを追加していけば確実に動作するシステムになります。
最初に、処理を定期実行するための「Schedule Trigger」ノードを追加します。設定画面では、実行頻度や時刻を選択できます。更新頻度は番組によって異なるため、状況に合わせた間隔にすると運用しやすくなります。実行時刻については、使用環境のタイムゾーン設定を確認したうえで指定する必要があります。
続いて「RSS Feed Read」ノードを追加し、Schedule Triggerと接続します。「URL」欄には、事前に確認したPodcastのRSS URLを入力します。テスト実行を行うと、タイトル・公開日・音声URLなどの要素が返される場合もあります。PodcastによってはRSS仕様が異なるため、取得データの構造を確認したうえで後続の処理に必要な項目を特定します。
PodcastのRSSには複数のエピソードが含まれるため、すべてを対象とすると処理量やコストが増える可能性があります。新着分のみを抽出するために、エピソード固有の識別子(GUID)や公開日時を基準に判定する方法がよく用いられます。
n8nでは「IF」ノードや「Code」ノードを使用して公開日時を比較できるものの、RSSによって日付形式が異なるケースもあり、取得後に日付形式を整える処理を挟むと判定しやすくなります。GUIDが提供されていない番組もあるため、その場合はタイトルや公開日時を組み合わせた判定など、複数の条件を使う方法があります。
過去に処理したエピソードを別の場所(スプレッドシートなど)に保管して照合する方法もありますが、データ量が多い場合はパフォーマンスに影響を与える可能性があります。運用の規模に応じて適切な判定方法を選択することが重要です。
新しいエピソードが判定できたら、音声データを取得し文字起こし処理に進みます。「HTTP Request」ノードで音声ファイルのURLを指定してダウンロードします。レスポンス形式をバイナリで受け取る設定にしておくと、後続のノードで扱いやすくなります。
次に「OpenAI」ノードを追加し、音声の文字起こしを行います。OpenAIの音声認識機能はファイルアップロード形式で動作するため、n8n側でバイナリデータを渡す設定が必要です。モデルにはWhisperを選択できます。言語設定を指定すると認識しやすくなる場合があります。
音声が長い場合やネットワーク状況によって処理時間が変わる可能性もあるため、タイムアウトを適切に調整しておくとエラーを避けやすくなります。
要約処理では、文字起こしされたテキストをわかりやすく整理するために「OpenAI」ノードを利用します。Resourceで「Chat」を選択し、目的に合ったモデルを設定します。長文になる場合が多いため、トークンの上限が比較的多いモデルを選ぶと処理の安定性が高まるでしょう。
要約の品質はプロンプト内容に左右されるため、概要の要点整理や箇条書きでのポイント提示など、出力形式を具体的に記述します。また、文字数やスタイルを指定することで、読みやすい要約を得やすくなります。
テキスト量が多い場合は、一度に処理できるトークン数を超える可能性があるため、チャンクに分割するなどの工夫をとることでエラー回避につながります。
最後に、生成された要約を通知または保存する処理を設定します。「Slack」ノードを追加して認証設定を行い、投稿先のチャンネルを指定します。Slackではメッセージの形式を調整できるため、要約やリンクをまとめた読みやすい構成にできます。
併せて記録を残したい場合は「Google Sheets」ノードを追加し、行追加の設定を行います。日時やタイトル、要約など必要な項目を各カラムに割り当てます。スプレッドシートで扱うデータ量が多い場合は、列順がずれないように注意が必要です。
すべてのノードを接続し保存すると、指定したスケジュールに基づいてワークフローが実行されるようになります。
ワークフローは一度作れば終わりではありません。Podcast特有のデータの大きさや、外部APIの仕様変更などにより、エラーにつながる場合があります。安定して稼働させ続けるために、あらかじめ考慮しておくべき設定ポイントを解説します。
OpenAIのWhisper APIにはファイルサイズの上限があり、長時間のPodcastなど大きい音声データではエラーが起きる可能性があります。そのため、事前にエピソードの平均サイズを確認し、サイズの大きい音声が多い場合は対策が必要です。
n8nで音声を分割・圧縮する方法もありますが設定が複雑なため、まずはRSSに記載されたファイルサイズを基準にし、一定以上の場合は処理をスキップする分岐を設けると運用しやすくなります。
また、大容量ファイルが頻繁に発生する場合は、Whisper以外の文字起こしAPIを検討する方法もあります。サービスによってはGoogle Driveの公開リンクを使って処理できるものもあるため、要件やコストに応じて選択すると安定しやすくなります。
音声の文字起こしとLLMによる要約は、利用量に応じた従量課金制です。毎日複数の長時間エピソードを処理していると、想定以上のコスト増大を招く懸念があります。
コストを抑えるためには、まず文字起こしを行う前に「本当に必要なエピソードか」を厳選することが重要です。タイトルのキーワードでフィルタリングを行い、興味のあるトピックだけを処理対象にするだけでもコスト削減につながります。
また、要約に使用するモデルを、高性能な「gpt-4o」から軽量な「gpt-4o-mini」に切り替えることも有効です。単純な要約タスクであれば、軽量モデルでも十分に対応可能でしょう。定期的にOpenAIのUsage(利用状況)画面を確認し、予算内で収まっているかチェックする運用を心がけてください。
Podcastの配信システムによって、RSSフィード内の日付フォーマット(ISO8601など)が微妙に異なる場合があります。n8nのDate&Timeノードなどで日時をパース(解析)する際、このフォーマットの違いによりエラーが発生したり、日時の比較が正しく行われず新着判定に失敗したりすることがあります。
これを防ぐためには、取得した日時データを一度n8n共通の日付フォーマットに変換する処理を挟むのが確実です。「Date&Time」ノードを使用して、タイムゾーンを日本時間(Asia/Tokyo)に統一し、テキスト型ではなく日付型として比較を行うように設定してください。
また、日付だけに頼らず、エピソードごとに付与される一意のID(GUID)を判定基準にすることで、再配信や修正更新による重複通知のリスクを低減できるでしょう。
n8nを活用したPodcastの自動要約ワークフローは、現代のビジネスパーソンにとって有効な手段となるでしょう。設定には多少の慣れが必要ですが、一度構築してしまえば、日々の情報収集にかかる手間と時間の削減が期待できます。
音声コンテンツから得られるインサイトは、テキストメディアとは異なる視点や深さを持っています。その価値を逃さず、かつ効率的に自身の知識として取り込むために、ぜひ自動化に取り組んでみてください。まずは無料版のn8nや安価なAPIモデルを利用して、小さく始めてみることをおすすめします。
株式会社TWOSTONE&Sonsグループでは
60,000人を超える
人材にご登録いただいており、
ITコンサルタント、エンジニア、マーケターを中心に幅広いご支援が可能です。
豊富な人材データベースと創業から培ってきた豊富な実績で貴社のIT/DX関連の課題を解決いたします。



幅広い支援が可能ですので、
ぜひお気軽にご相談ください!

