DifyとLINEを連携してAIチャットボットを構築する方法を解説
自動化
2025.12.25


「n8n」とAI検索エンジン「Perplexity」を連携させ、最新ニュースの収集からGoogleスプレッドシートへの整理までを自動化する方法を解説します。 毎朝の情報収集ルーティンを効率化する「DX実践ガイド」として、具体的な手順を5つのステップでご紹介します。
「今朝のニュースは何かな…」
毎朝、出社してまず最初にニュースサイトを巡回していませんか?業界の最新動向、競合他社の動き、技術トレンド…。情報収集は重要な業務ですが、毎日同じ作業の繰り返しに時間を取られてしまいます。
この記事では、AI検索エンジン「Perplexity(パープレキシティ)」とノーコードツール「n8n」を組み合わせて、最新ニュースの収集からGoogleスプレッドシートへの整理まで、すべてを自動化する方法を詳しく解説します。
特徴 | Perplexity | n8n | 組み合わせ効果 |
|---|---|---|---|
情報収集力 | 最新情報を高精度で検索 | 定期実行で自動化 | 24時間365日、最新情報を自動収集 |
信頼性 | 情報源を明記して回答 | エラー処理機能 | 信頼できる情報だけを確実に蓄積 |
カスタマイズ性 | プロンプトで検索内容を調整 | ワークフローを自由設計 | 業務に最適な情報収集システムを構築 |
コスト | APIは従量課金制(3ドル〜) ※2025年10月現在 | 無料プランあり | 最小限のコストで運用可能 |
実際の活用シーンをご紹介します。
それでは、実際にシステムを構築していきましょう。
n8nには2つの利用方法がありますが、本記事では初心者の方でもすぐに始められるクラウド版を使用しています。
利用方法 | 特徴 | おすすめ度 | 適している人 |
|---|---|---|---|
クラウド版 | • ブラウザからすぐに利用可能• インストール不要• サーバー管理不要• 月5ワークフローまで無料 | ★★★ | 初心者〜中級者すぐに始めたい方 |
セルフホスト版 | • 自分のPCやサーバーで運用• 完全無料で利用可能• 高度なカスタマイズが可能• 技術知識が必要 | ★★☆ | 上級者大規模運用したい方 |
この章では、ワークフロー構築に必要な3つのツールの準備方法を画像付きで詳しく解説します。
システム構築に必要なものをまとめました。
それぞれの役割と準備にかかる時間の目安も記載しています。
必要なもの | 役割 | 費用 |
|---|---|---|
PerplexityのAPIキー | AI検索エンジンへのアクセス権 | 3ドル~ |
GoogleのAPI連携設定 | n8nとGoogleサービスの接続 | 無料 |
Googleスプレッドシート | 収集したデータの保存先 | 無料 |
PerplexityのAPIを利用するには、最低3ドル分のクレジット購入が必要です。※2025年10月現在
これは1回だけの課金で数百回の検索が可能なので、テストには十分です。
Step 1:Perplexityに無料登録
まずはPerplexityのアカウントを作成します。

Gmailアカウントを使えば手間をかけず登録完了
Step 2:API利用のための情報登録
APIキーを取得するための基本情報を登録します。
入力項目 | 記入例 | 備考 |
|---|---|---|
グループ名 | News Collection | 任意の名前でOK |
利用目的 | ニュース収集の自動化 | 簡単な説明でOK |
会社名 | 個人利用 | 個人の場合は「個人利用」と記入 |
メールアドレス | ◯◯◯◯@gmail.com | 登録時のメールアドレス |
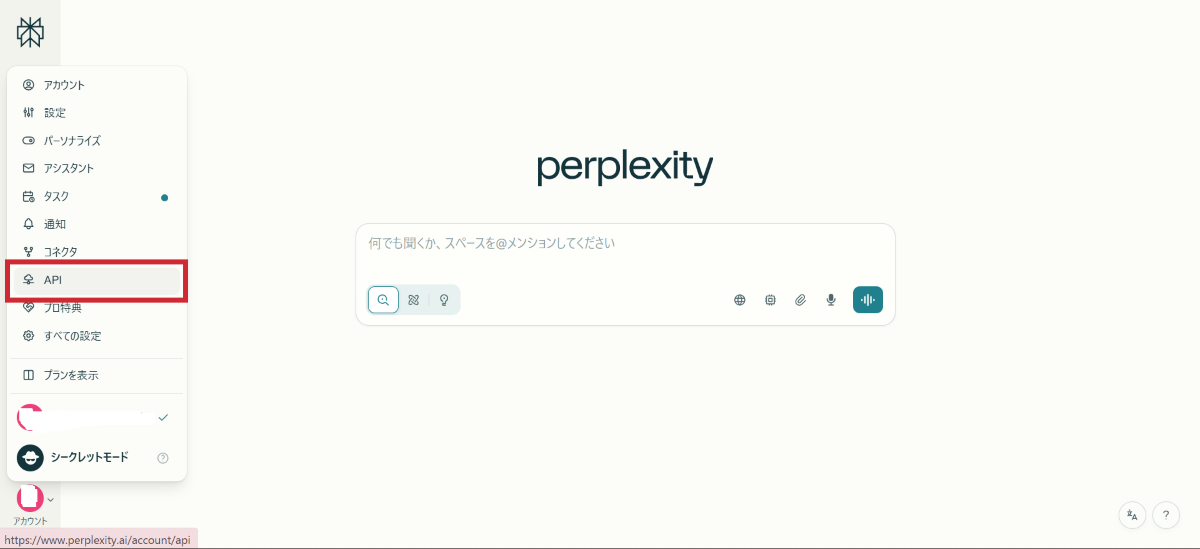

必須項目をすべて埋めて保存
Step 3:決済情報の登録とクレジット購入
次に、APIを利用するための決済情報を登録します。
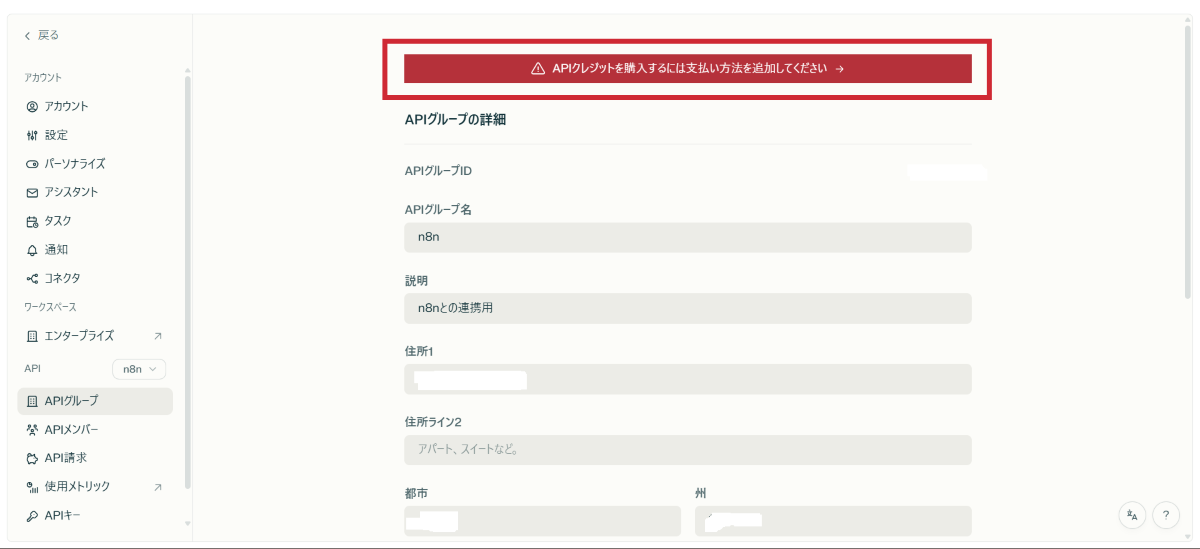
決済方法の選択
決済方法 | 最低購入額 | おすすめ度 | 備考 |
|---|---|---|---|
クレジットカード | 3ドル | ★★★ | 即時利用可能、最も簡単 |
銀行振込 | 5ドル | ★☆☆ | 処理に時間がかかる |
Link | 3ドル | ★★☆ | 米国の決済サービス |
クレジット購入の手順
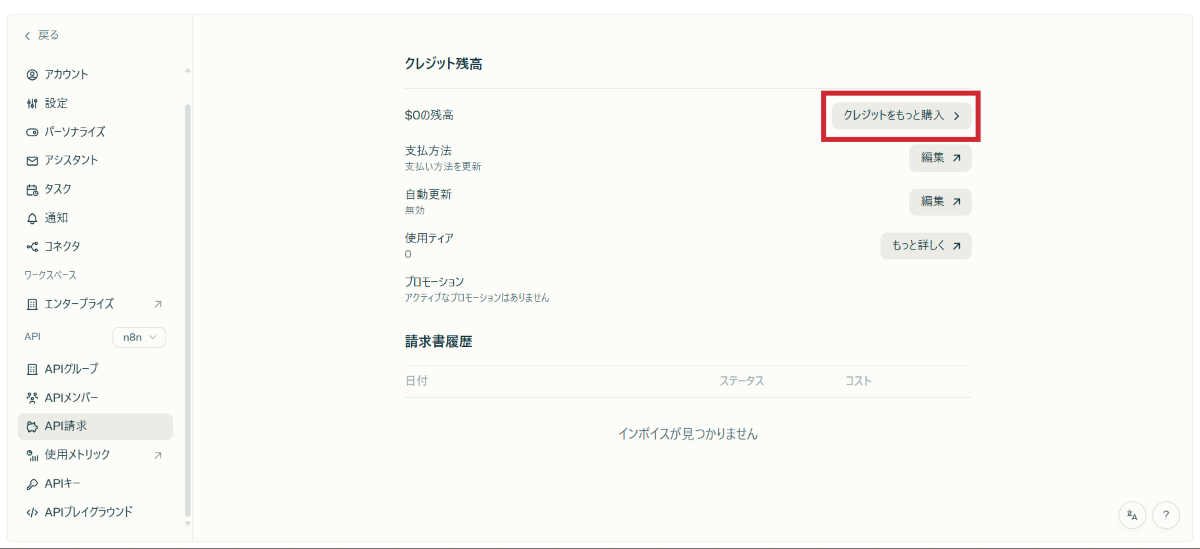

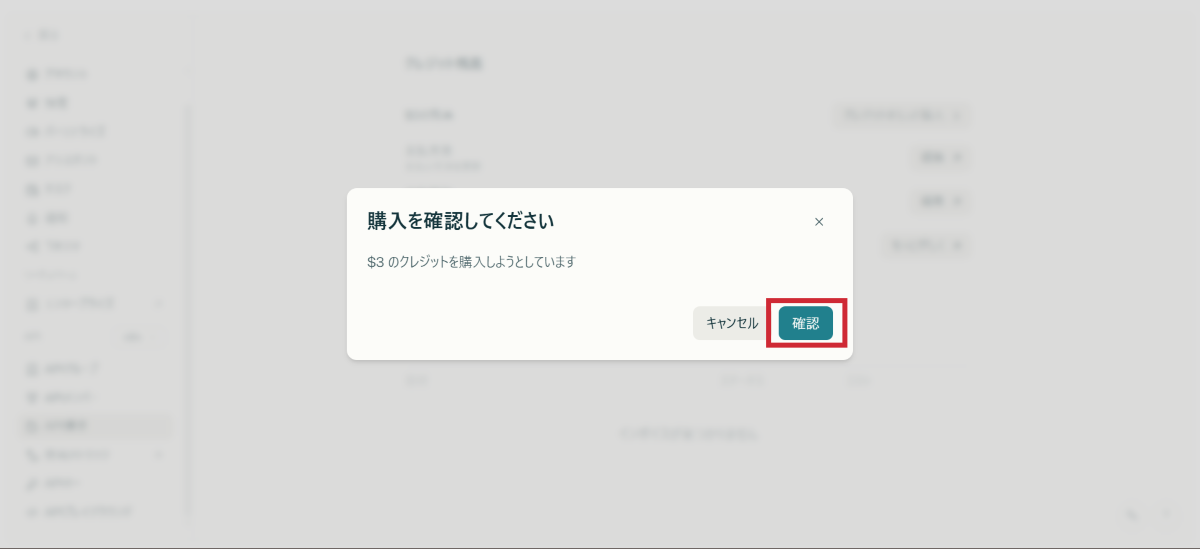
3ドル分のクレジットで数百回の検索が可能 ※2025年10月現在
Step 4:APIキーの取得と保管
いよいよAPIキーを取得します。
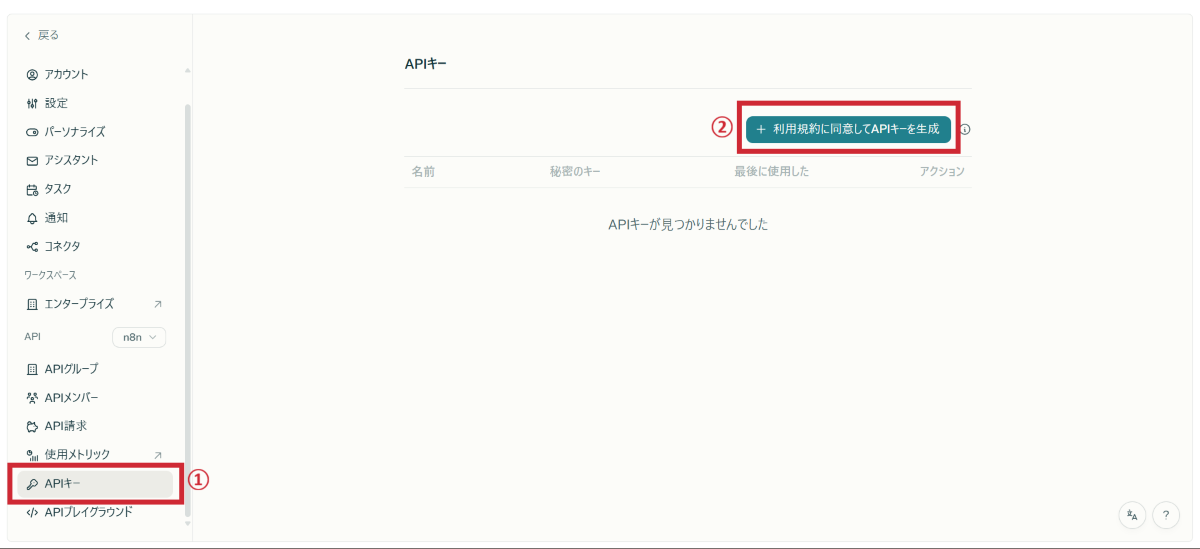
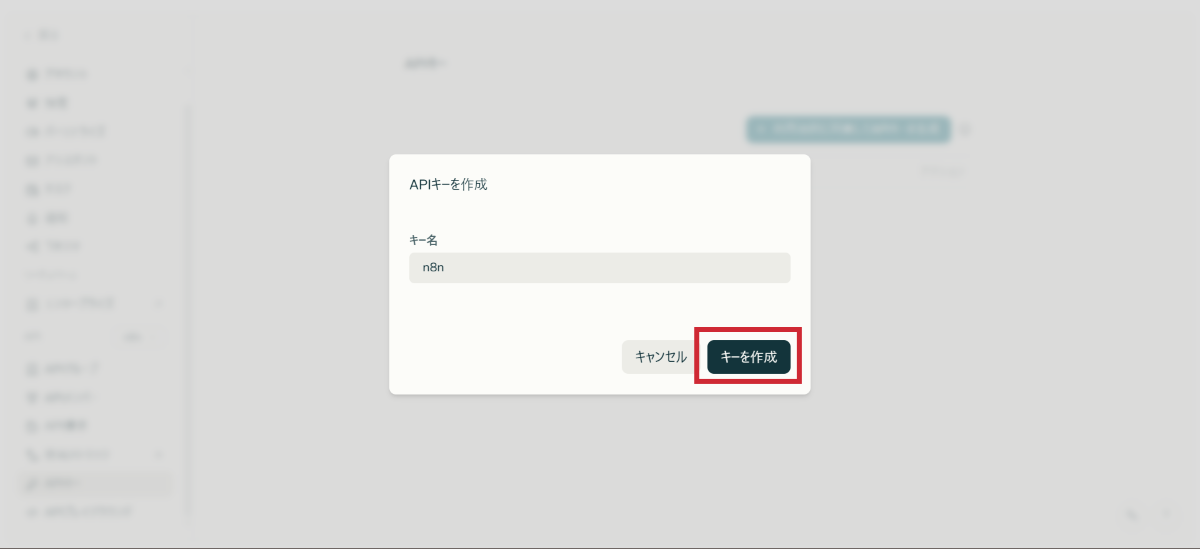
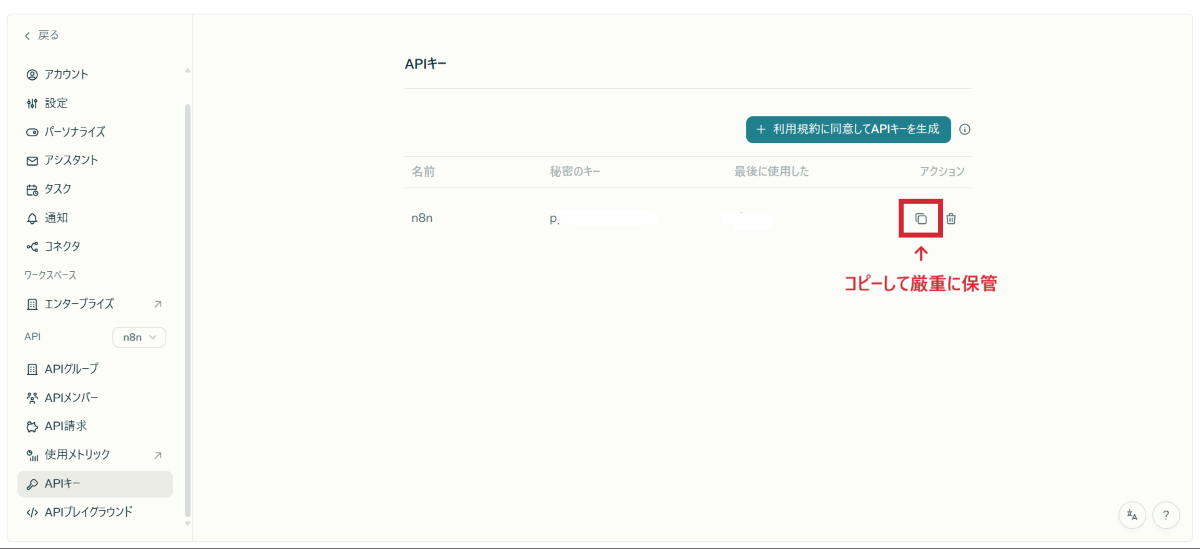
APIキーは一度しか表示されないので、必ずコピーして保管
セキュリティ上の重要な注意
GoogleのAPI連携は、n8nの設定画面から直接行えるため、事前準備は不要です。詳細はSTEP4で解説します。
収集したニュースを保存するスプレッドシートを作成しましょう。
スプレッドシートの作成手順
基本設定
スプレッドシートの列の設定
列 | 1行目の入力内容 | 用途 |
|---|---|---|
A列 | 公開日 | ニュースが公開された日付 |
B列 | 記事タイトル | ニュースのタイトル |
C列 | 記事URL | 元記事へのリンク |
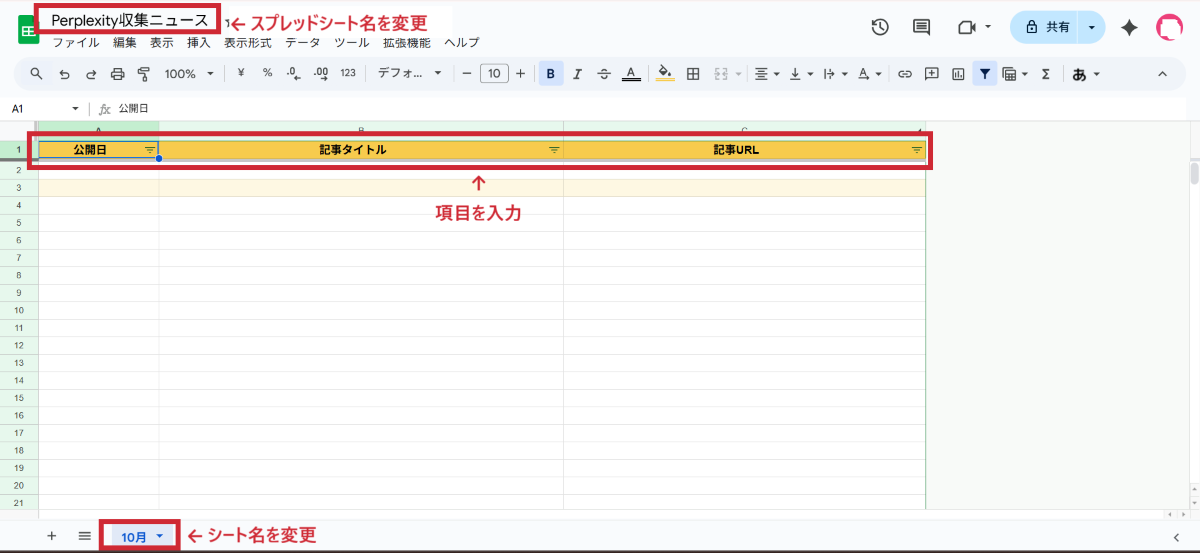
このような形式でスプレッドシートを準備
応用のヒント
準備が完了したら、いよいよワークフローの構築に進みましょう。
この章では、実際に手を動かしながらn8nでワークフローを構築していきます。
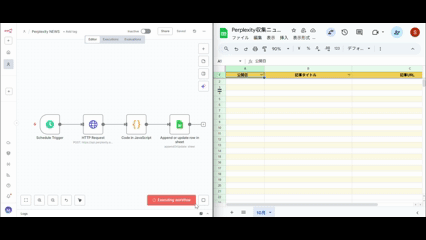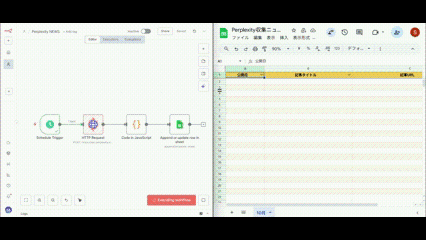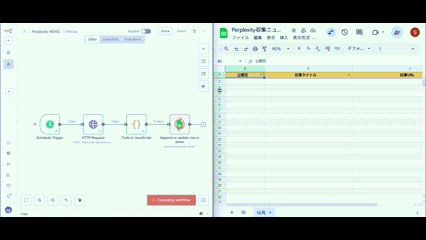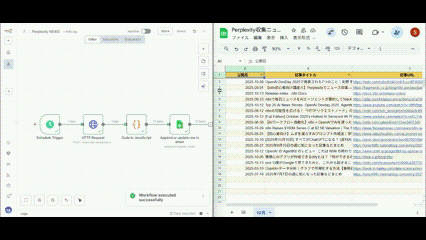
ワークフロー全体の流れ
構築するワークフローの全体像を理解しておきましょう。
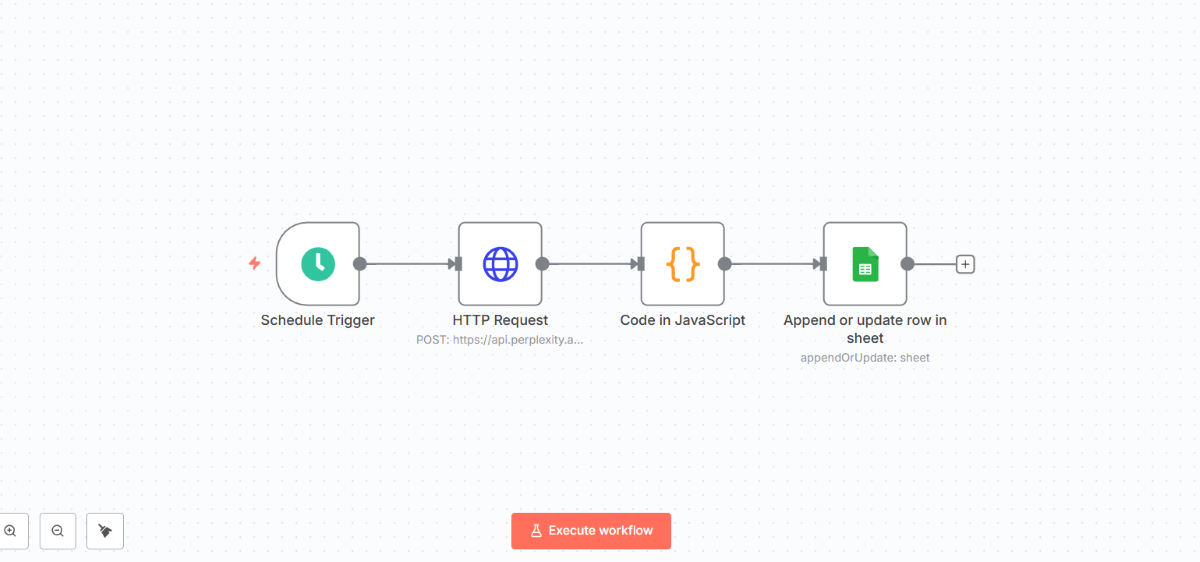
5つのノードが連携して自動化を実現
初期設定:n8nワークスペースの準備
わかりやすい名前をつけておくと管理が楽になります
最初に、いつニュースを収集するかを設定します。Schedule Triggerノードを使うことで、決まった時間に自動実行できるようになります。
Schedule Triggerの追加と設定
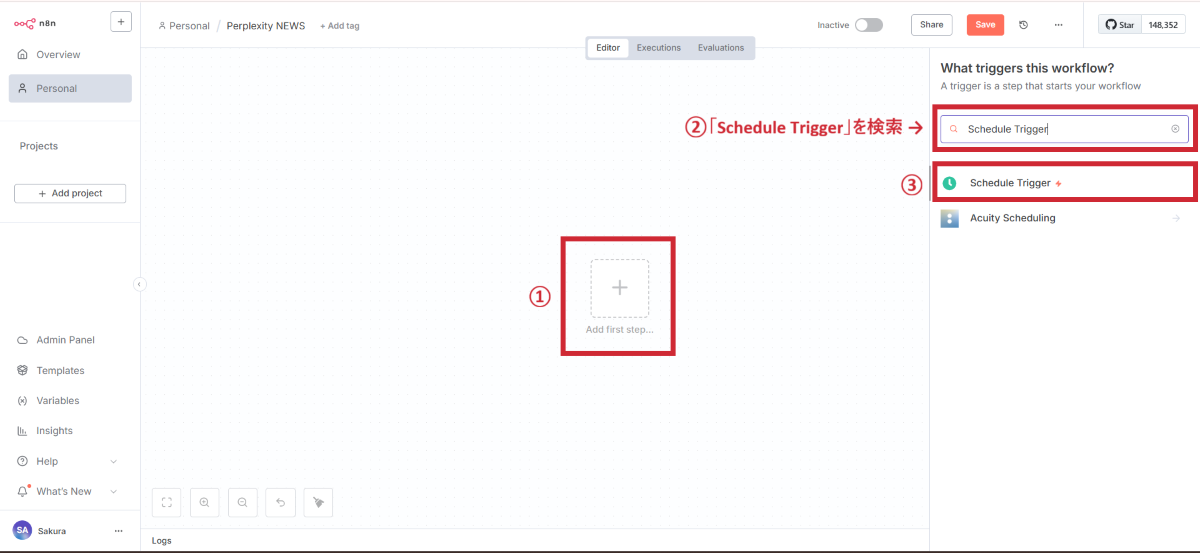
タイミングの設定
設定項目 | 設定値 | 説明 |
|---|---|---|
Trigger Interval | Week | 週単位で実行 |
Week Days | Monday | 月曜日を選択 |
Hour | 9 | 午前9時 |
Minute | 0 | 0分(9:00ちょうど) |
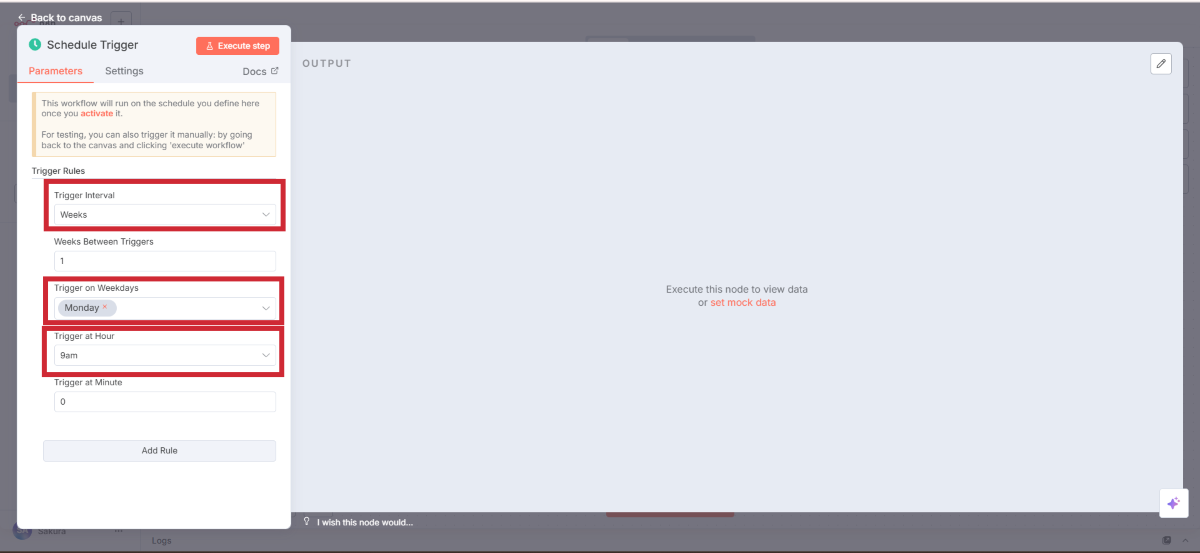
毎週月曜日の朝9時に自動実行される設定
カスタマイズ例
設定が完了したら「Back to canvas」をクリックしてキャンバスに戻ります。
次に、Perplexityと通信するための設定を行います。HTTP Requestノードは、外部サービス(今回はPerplexity)のAPIを呼び出すための重要なノードです。
HTTP Requestノードの追加
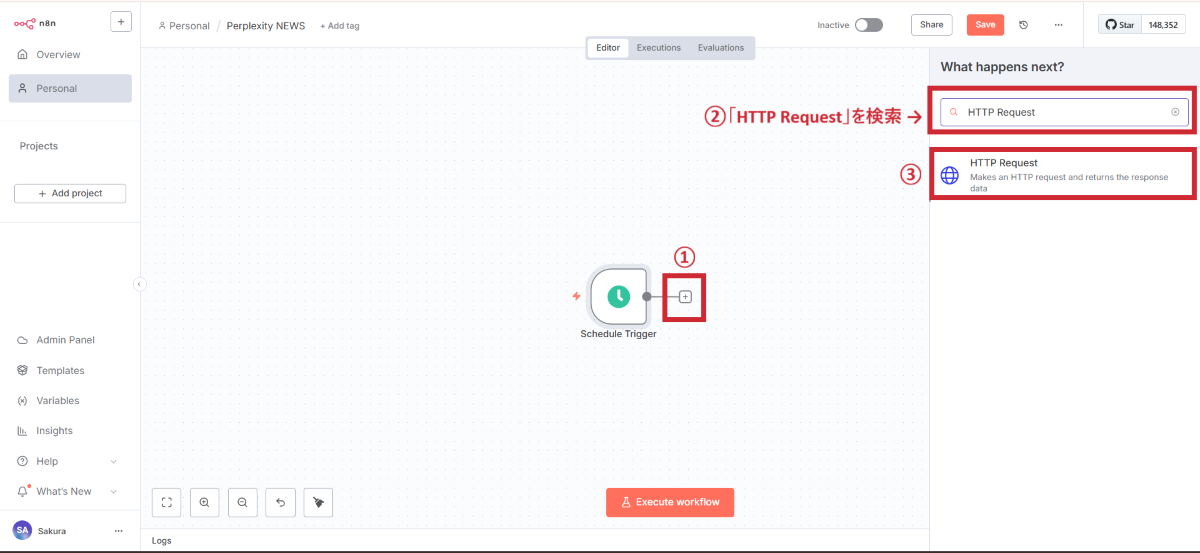
基本設定
HTTP Requestノードの設定画面で、以下を入力します。
設定項目 | 設定値 | 説明 |
|---|---|---|
Method | POST | データを送信するため |
URL | [https://api.perplexity.ai/chat/completions](https://api.perplexity.ai/chat/completions) | PerplexityのAPIエンドポイント |
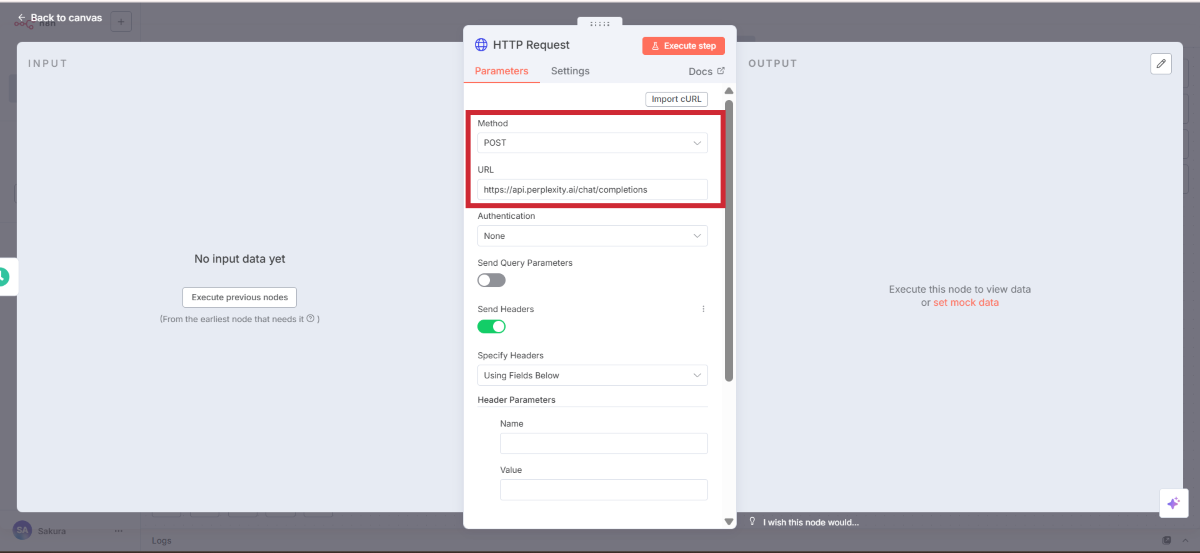
MethodをPOSTに変更することを忘れずに
認証情報(Header)の設定
APIキーを使って認証を行う設定をします。
項目 | 入力値 | 説明 |
|---|---|---|
Name | Authorization | 認証情報を送るための標準的な名前 |
Value | Bearer YOUR_API_KEY | “Bearer “の後に取得したAPIキーを入力 |
注意
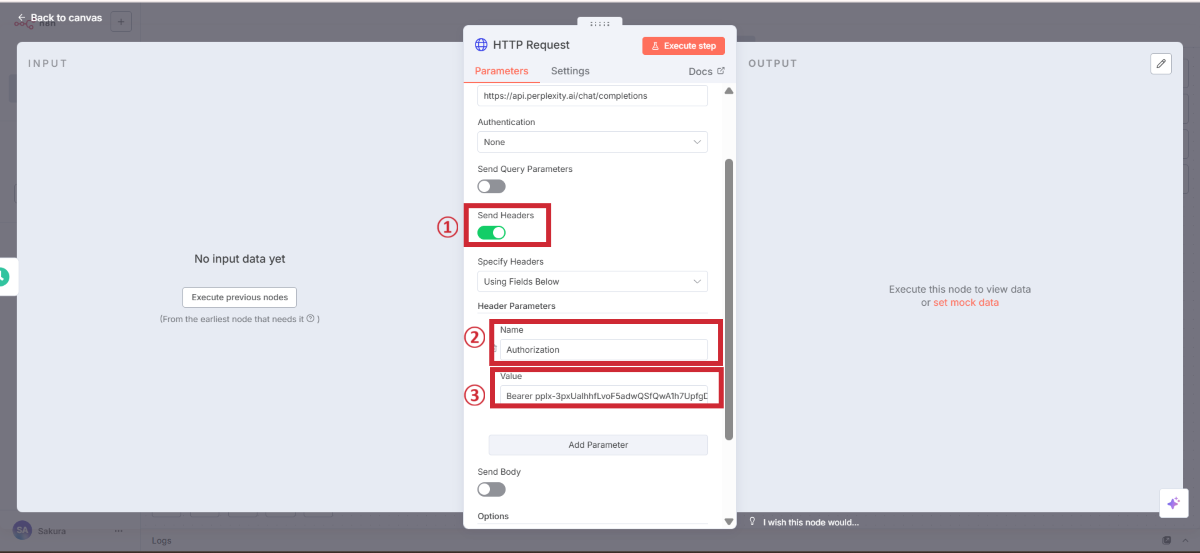
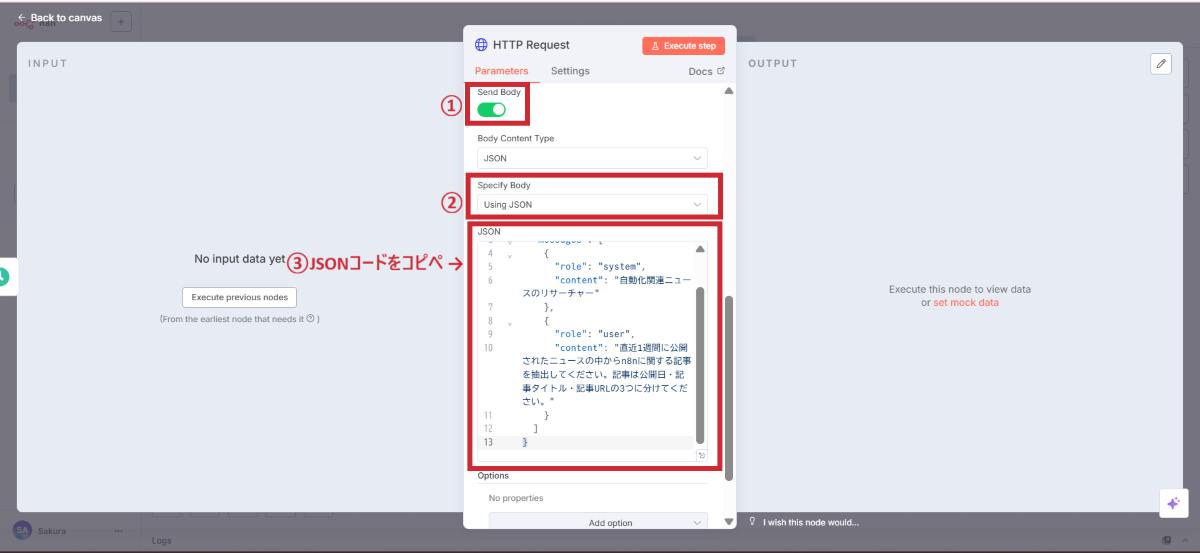
リクエスト内容(Body)の設定
Perplexityへの指示内容を設定します。
{ “model”: “sonar”, “messages”: [ { “role”: “system”, “content”: “自動化関連ニュースのリサーチャー” }, { “role”: “user”, “content”: “直近1週間に公開されたニュースの中からn8nに関する記事を抽出してください。記事は公開日・記事タイトル・記事URLの3つに分けてください。” } ] } |
|---|
モデルの選択ガイド
用途に応じて最適なモデルを選択できます。
モデル名 | 特徴 | 適している用途 |
|---|---|---|
sonar | 高速・低コスト | 日常的なニュース収集 |
sonar-pro | 高精度・引用元充実 | 重要な調査・レポート作成 |
sonar-reasoning | 論理的推論が得意 | 分析・考察が必要な調査 |
sonar-deep-research | 最高精度・詳細調査 | 学術調査・競合分析 |
動作テスト
設定が完了したら「Execute step」をクリックして動作確認をします。
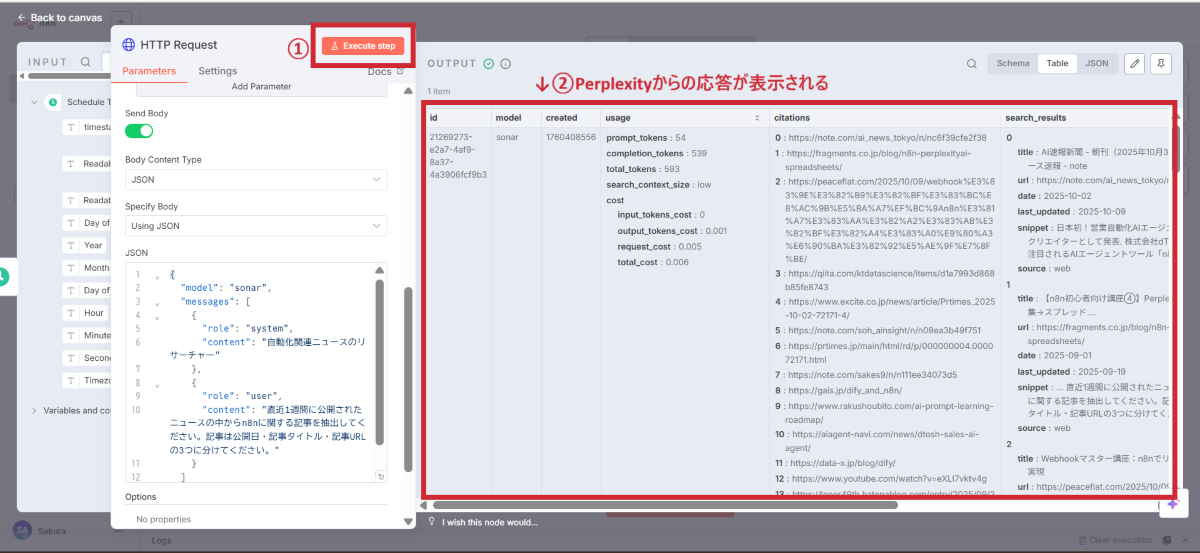
正常に動作すると、右側にPerplexityからの応答が表示されます
トラブルシューティング
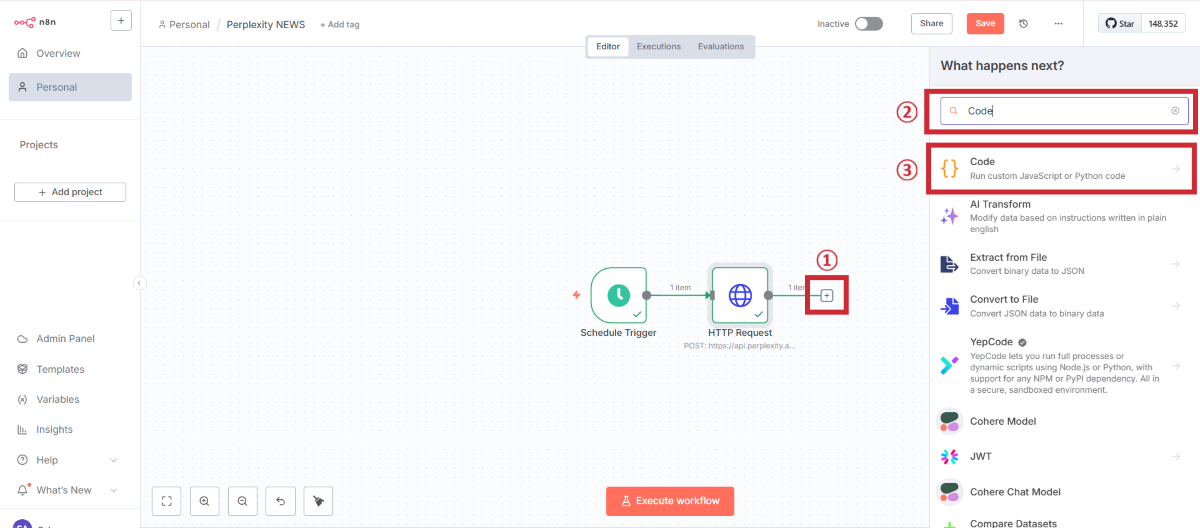
Perplexityから取得したデータは、そのままではスプレッドシートに書き込みにくい形式です。Codeノードを使って、データを整形します。
Codeノードの追加
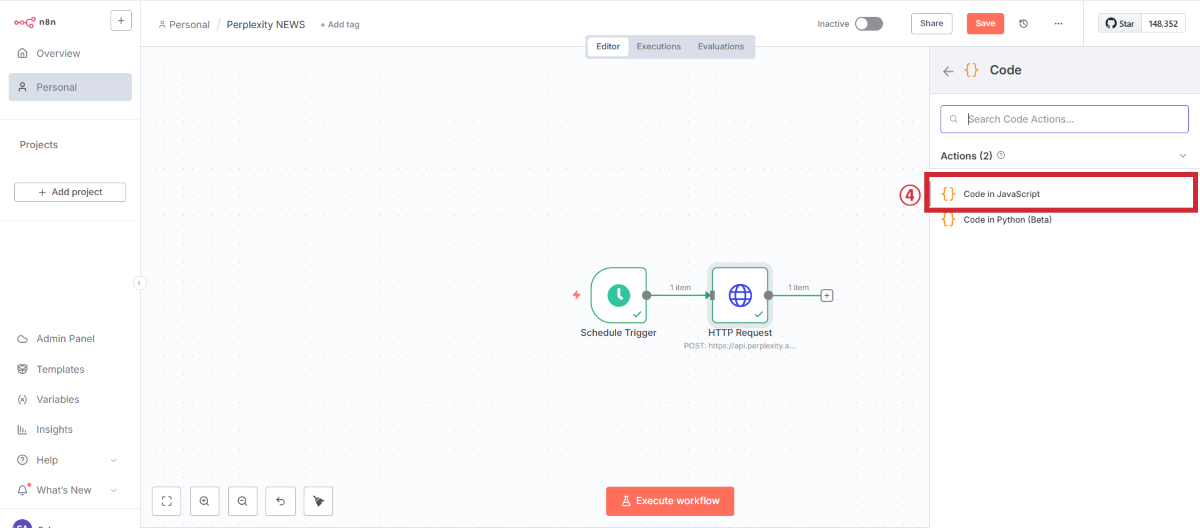
JavaScriptコードの設定
const items = $input.all(); const outputData = []; for (let i = 0; i < items.length; i++) { const item = items[i].json; // search_results から title, url, date を抽出 if (item.search_results && Array.isArray(item.search_results)) { for (const result of item.search_results) { if (result.title && result.url && result.date) { outputData.push({ json: { ‘記事タイトル’: result.title, ‘参照URL’: result.url, ‘公開日’: result.date } }); } else if (result.title && result.url) { // dateがない場合は空文字列で対応 outputData.push({ json: { ‘記事タイトル’: result.title, ‘参照URL’: result.url, ‘公開日’: ” } }); } } } // choices[0].message.content からテキストパースして抽出する部分 // search_resultsにデータがあるため、基本的には不要ですが、 // content内にsearch_resultsにはない特別な情報が含まれる場合にのみ有効にしてください。 // 必要なければこのブロック全体をコメントアウトまたは削除してください。 if (item.choices && item.choices[0] && item.choices[0].message && item.choices[0].message.content) { const content = item.choices[0].message.content; const articleBlocks = content.split(‘—\n\n’).filter(block => block.trim() !== ”); for (const block of articleBlocks) { const dateMatch = block.match(/\*\*公開日:\*\* (.*?)\s*$/m); const titleMatch = block.match(/\*\*記事タイトル:\*\*([\s\S]*?)(?=\n\n\*\*内容要約\*\*|\n—|$)/); const urlMatch = block.match(/\*\*参照URL\*\* \n(https?:\/\/[^\s]+)/); const date = dateMatch && dateMatch[1] ? dateMatch[1].trim() : ‘N/A’; const title = titleMatch && titleMatch[1] ? titleMatch[1].trim() : ‘N/A’; const url = urlMatch && urlMatch[1] ? urlMatch[1].trim() : ‘N/A’; if (title !== ‘N/A’ && url !== ‘N/A’ && date !== ‘N/A’) { outputData.push({ json: { ‘記事タイトル’: title, ‘参照URL’: url, ‘公開日’: date } }); } } } } return outputData; |
|---|
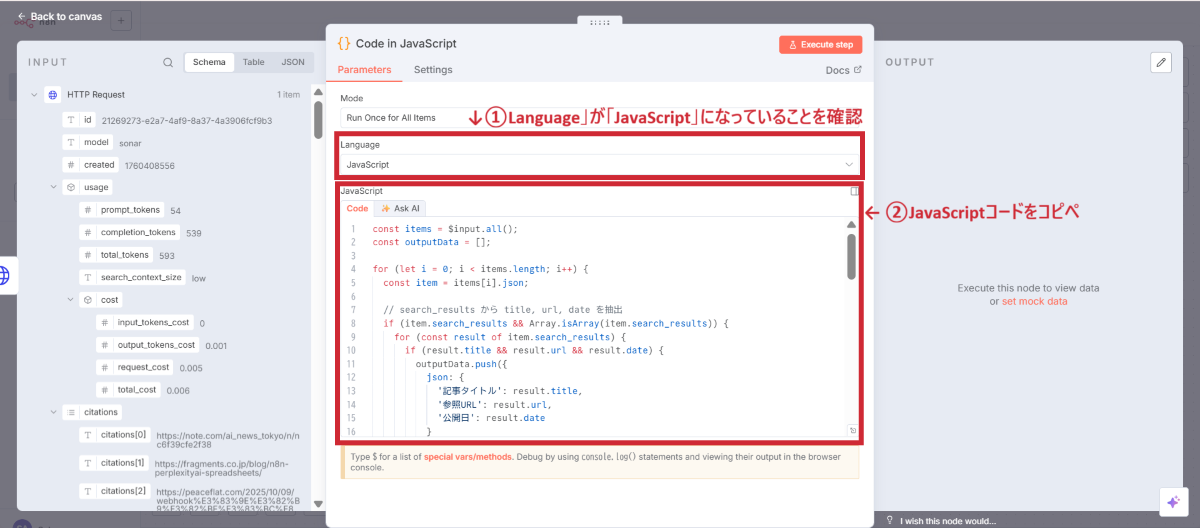
コードの動作確認
「Execute step」をクリックして、データが正しく整形されていることを確認します。

整形されたデータが表形式で表示されます
このコードが行っていること
最後に、整形したデータをGoogleスプレッドシートに自動で書き込む設定を行います。
Google Sheetsノードの追加
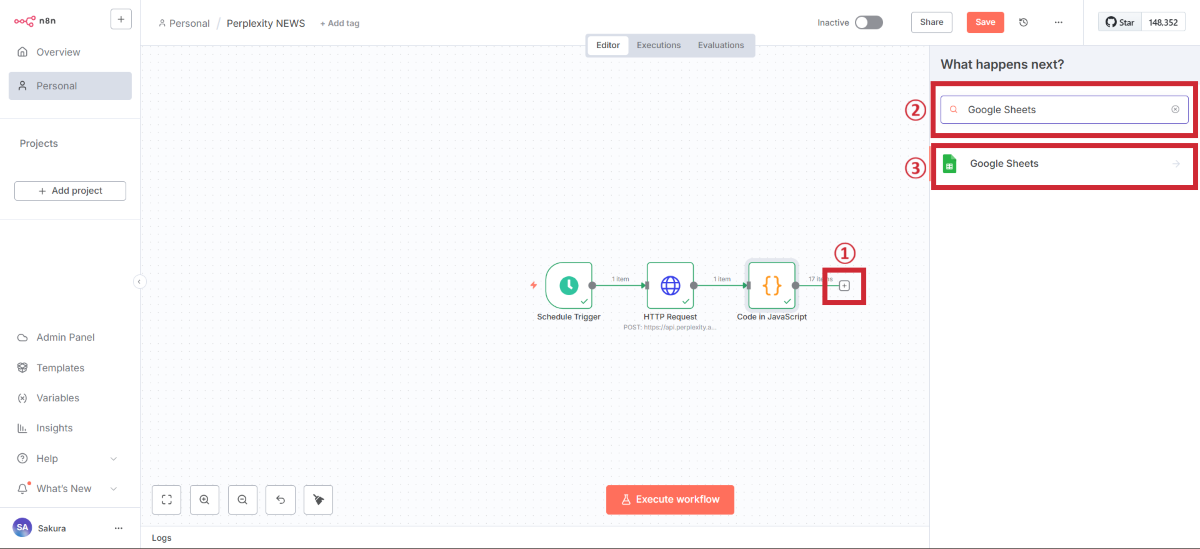
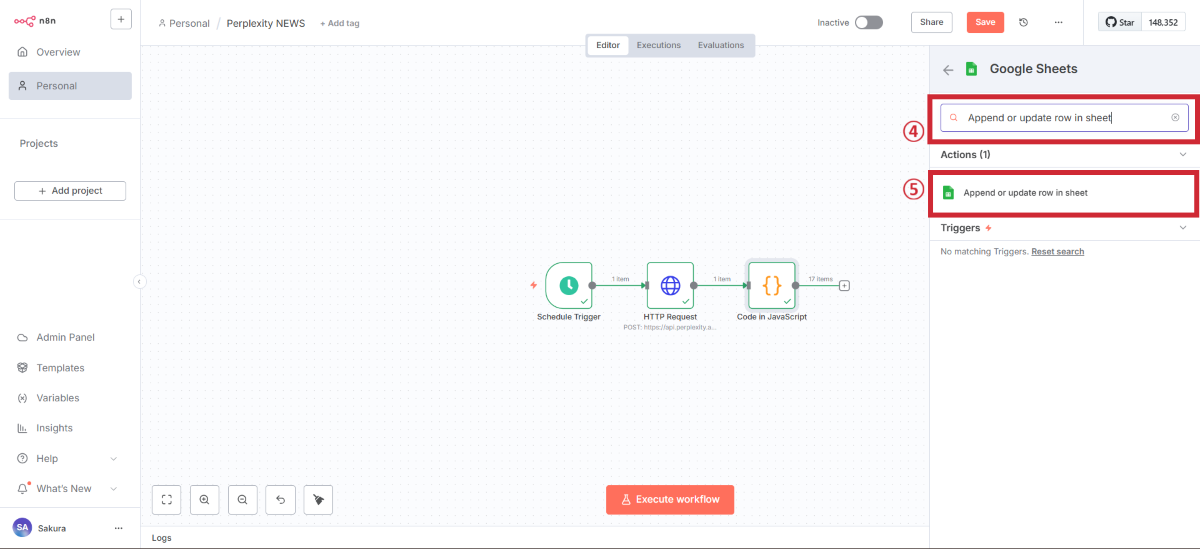
Google認証の設定(初回のみ)
初めてGoogle Sheetsを使う場合は、認証が必要です。
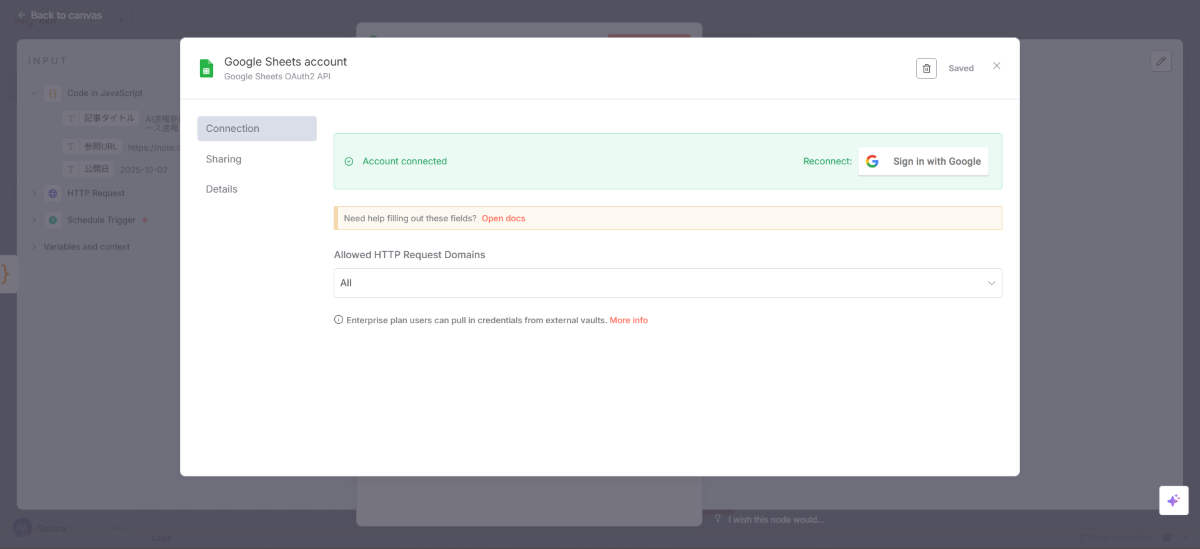
Googleアカウントと連携して、スプレッドシートへのアクセスを許可
Google Sheetsノードの設定
以下の設定を行います。
設定項目 | 設定値 | 説明 |
|---|---|---|
Document | Perplexity収集ニュース | 第1章で作成したスプレッドシート |
Sheet | 10月(または現在の月) | データを書き込むシート |
Mapping Column Mode | Map Each Column Manually | 列を個別に指定 |
Column to Match On | 記事タイトル | 重複チェックの基準列 |
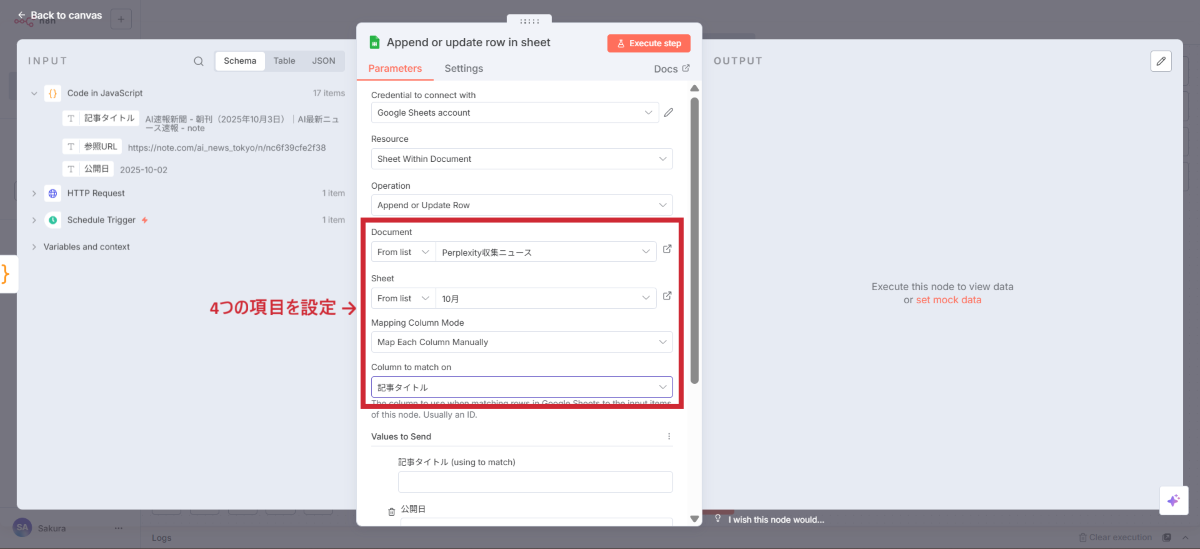
データマッピングの設定
各列にどのデータを入れるかを指定します。
スプレッドシートの列 | マッピングするデータ |
|---|---|
A(公開日) | Codeノードの「公開日」をドラッグ&ドロップ |
B(記事タイトル) | Codeノードの「記事タイトル」をドラッグ&ドロップ |
C(記事URL) | Codeノードの「記事URL」をドラッグ&ドロップ |
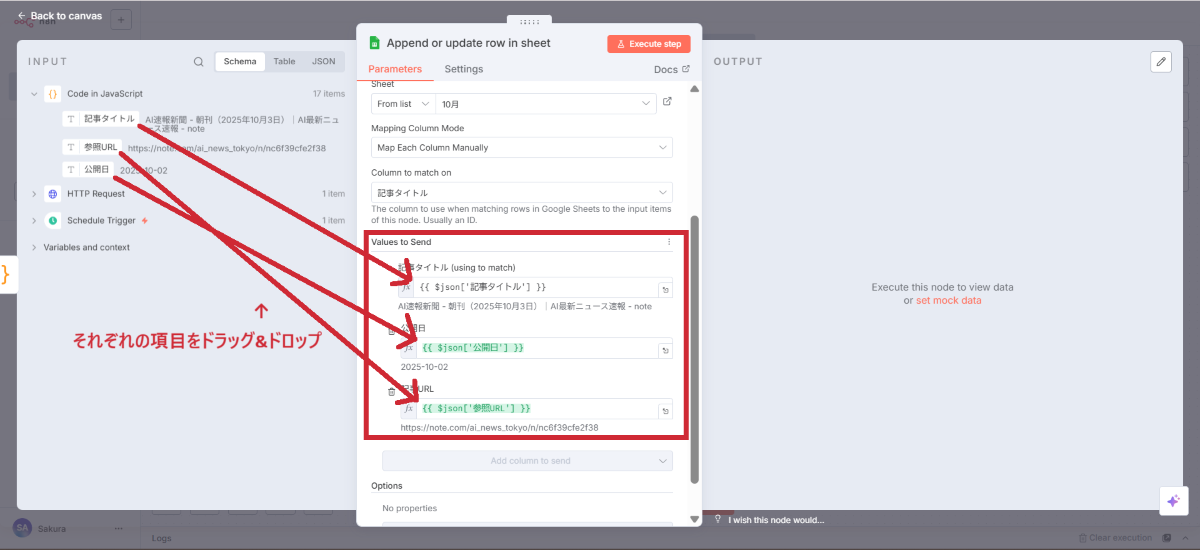
ドラッグ&ドロップで簡単にマッピング設定
すべての設定が完了したら、ワークフロー全体を実行してテストしましょう。
実行前のチェックリスト
ワークフローの実行
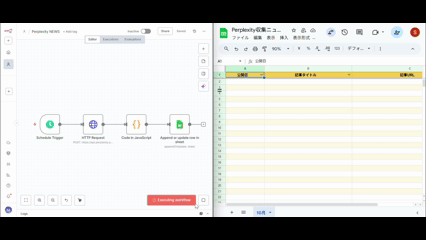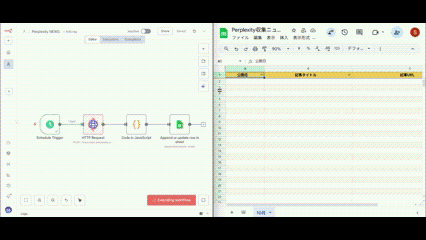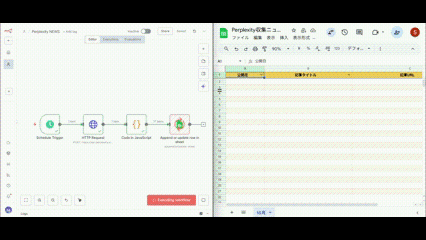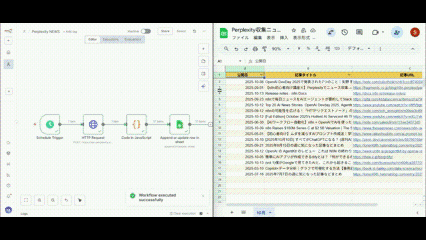
すべてのノードが正常に動作すると緑色で表示されます
Googleスプレッドシートの確認
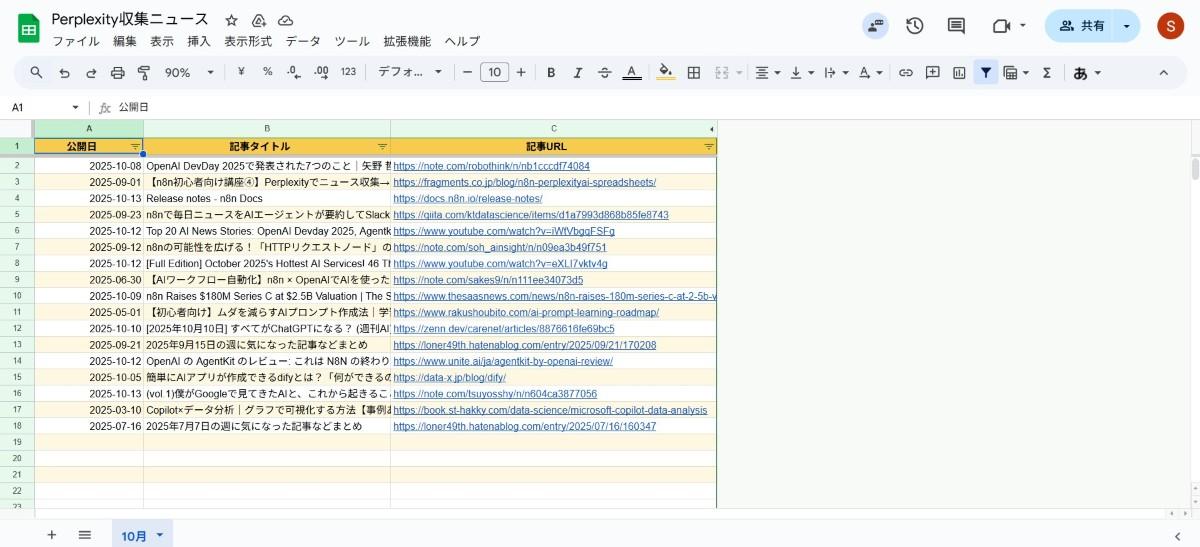
ニュースが自動的に整理されて保存されています
動作の仕組み
ワークフローの有効化
テストが成功したら、定期実行を有効にします。
この章では、よくある問題の解決方法と、基本システムをカスタマイズする方法を紹介します。
構築時に遭遇しやすい問題をまとめました。
エラー内容 | 原因 | 解決方法 | 確認ポイント |
|---|---|---|---|
APIキーエラー(401) | APIキーの入力ミス | Bearer の後の半角スペースを確認APIキーを再度コピー&ペースト | “Bearer “の後にスペースがあるか |
レート制限(429) | API呼び出し回数の超過 | 暫く待って再実行クレジットを追加購入 | 残りクレジットの確認 |
データが空(No data) | プロンプトの問題 | 検索キーワードを変更期間を広げる(1週間→2週間) | Perplexityの応答を確認 |
スプレッドシート書き込みエラー | 権限不足 | Google認証を再設定スプレッドシートの共有設定確認 | 編集権限があるか |
重複データ | マッチング列の設定ミス | Column to Match Onを確認「記事タイトル」を選択 | 一意性のある列を選択 |
日本語が文字化け | エンコーディングの問題 | JSONのcharsetを確認UTF-8を指定 | Codeノードの出力確認 |
基本システムをベースに、業務に合わせたカスタマイズが可能です。
検索キーワードのカスタマイズ例
用途に応じて、HTTP RequestノードのJSONを変更します。
『競合分析用』
{ “model”: “sonar-pro”, “messages”: [ { “role”: “user”, “content”: “直近1週間の[競合企業名]に関するニュースリリースと製品発表を収集してください。プレスリリース、新製品、提携、買収などの情報を含めてください。” } ] } |
|---|
『技術トレンド調査用』
{ “model”: “sonar”, “messages”: [ { “role”: “user”, “content”: “直近1週間のAI・機械学習・生成AIに関する技術ニュースを収集してください。特に実用化事例と新しいツール・サービスに焦点を当ててください。” } ] } |
|---|
『業界動向調査用』
{ “model”: “sonar-deep-research”, “messages”: [ { “role”: “user”, “content”: “[業界名]業界の直近1ヶ月の重要な動向を調査してください。M&A、規制変更、新規参入、市場規模などの情報を含めてください。” } ] } |
|---|
高度な活用方法
実装方法 | メリット | 設定のポイント |
|---|---|---|
HTTP Requestノードを複数配置 | テーマごとに異なる検索が可能 | 各ノードで異なるプロンプト設定 |
ループ処理を実装 | 効率的に複数検索を実行 | Codeノードでループ処理 |
条件分岐を追加 | 曜日によって検索内容を変更 | IF Nodeを活用 |
収集したニュースを自動で通知する機能を追加できます。
スプレッドシートの高度な活用
自動集計機能の追加
追加する列 | 関数例 | 用途 |
|---|---|---|
カテゴリ | =IF(SEARCH(“AI”,B2),”AI”,”その他”) | 自動分類 |
重要度 | =IF(SEARCH(“発表”,B2),”高”,”中”) | 優先順位付け |
要約 | Perplexityで要約を生成 | 概要把握 |
関連部署 | VLOOKUPで自動判定 | 情報共有の効率化 |
お疲れ様でした。本記事では、Perplexityとn8nを組み合わせた自動ニュース収集システムの構築方法を詳しく解説しました。
このシステムがもたらす価値
構築したシステムは、以下のような価値を提供します。
導入前 | 導入後 | 改善効果 |
|---|---|---|
毎朝のニュースチェック | 自動収集で時短に | 作業時間の削減 |
重要な情報の見落とし | 網羅的な自動収集 | 情報収集の精度向上 |
情報共有の手間 | スプレッドシートで自動共有 | チーム生産性の向上 |
手動でのデータ整理 | 自動で構造化データ化 | 分析可能なデータ蓄積 |
次のステップ
基本システムの構築に成功したら、以下のステップに挑戦してみてください。
Level 1:基本の改善
Level 2:機能拡張
Level 3:高度な自動化
活用のヒント
さらなる学習リソース
このシステムは、少しのカスタマイズで市場調査、競合分析、トレンド把握など、幅広い情報収集業務に応用できます。
ぜひ、あなたの業務に最適な形にカスタマイズして、情報収集の効率化を実現してください。
—
本記事が皆様の業務効率化のお役に立てれば幸いです。
今後は、AIやクラウド技術を活用した革新的な方法で業務を効率化し、業績を向上させる企業が生き残るでしょう。
株式会社TWOSTONE&Sonsグループでは
60,000人を超える
人材にご登録いただいており、
ITコンサルタント、エンジニア、マーケターを中心に幅広いご支援が可能です。
豊富な人材データベースと創業から培ってきた豊富な実績で貴社のIT/DX関連の課題を解決いたします。



幅広い支援が可能ですので、
ぜひお気軽にご相談ください!