DifyとLINEを連携してAIチャットボットを構築する方法を解説
自動化
2025.12.25


「社内の膨大な資料から必要な情報を瞬時に引き出す」RAGチャットボットをn8nでノーコード構築します。情報検索と回答生成を自動化し、社内の知識管理を次世代へ引き上げるDXガイドです。
「社内の膨大な資料から、必要な情報を瞬時に引き出せたら…」
現代のビジネスでは、マニュアル、規定書、技術文書、FAQ、議事録など、膨大な文書が日々生成されています。しかし、これらの情報は散在し、必要な時に素早くアクセスすることが困難です。
本記事では、RAG(Retrieval-Augmented Generation:検索拡張生成)技術を活用し、n8nで社内ナレッジを活用したAIチャットボットを構築する方法を、初心者でも実装できるよう詳しく解説します。
出典:RAG技術解説
RAGチャットボットは、従来の情報管理やカスタマーサポートにおける多くの課題を解決し、ビジネスに大きな効果をもたらします。
従来の課題 | RAGによる解決 | ビジネス効果 |
|---|---|---|
情報の散在 | 一元的な知識ベースから即座に検索 | 検索時間を大幅削減 |
古い情報の参照 | 常に最新のドキュメントを参照 | 情報の正確性向上 |
専門知識の属人化 | 組織の知識を全員が活用可能 | ナレッジの民主化 |
回答の一貫性欠如 | 同じ情報源から一貫した回答 | 品質の標準化 |
24時間対応の限界 | いつでも即座に正確な回答 | 顧客満足度向上 |
通常のAIチャットボットが学習済みの一般知識のみに基づいて一般的な回答をするのに対し、RAGチャットボットは自社の最新ドキュメントを参照し、組織固有の正確な回答を生成できます。
比較項目 | 通常のAIチャットボット | RAGチャットボット |
|---|---|---|
情報源 | 学習済みの一般知識のみ | 自社の最新ドキュメント |
回答の正確性 | 一般的な回答 | 組織固有の正確な回答 |
更新頻度 | AIモデルの更新時のみ | リアルタイムで更新可能 |
カスタマイズ性 | 限定的 | 完全にカスタマイズ可能 |
運用コスト | 低〜中 | 低(ノーコードで構築) |
実際の活用シーンを具体的に見てみましょう。
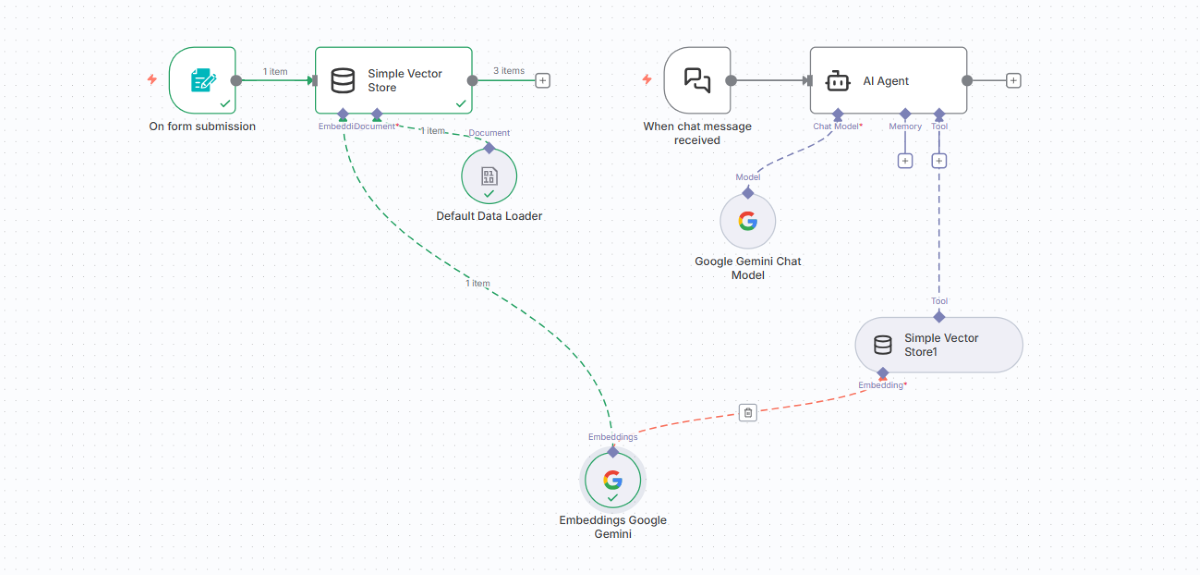
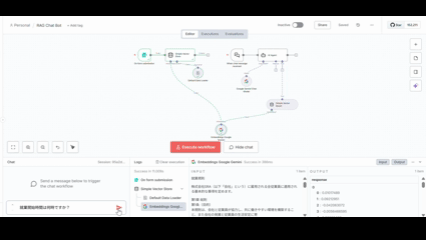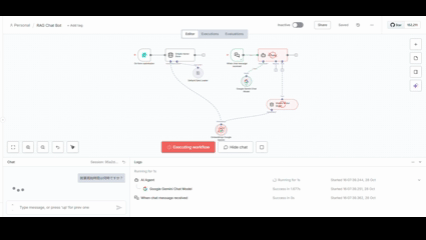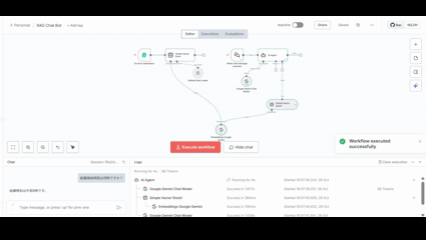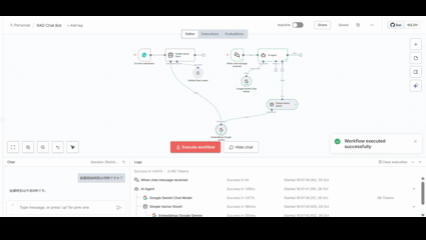
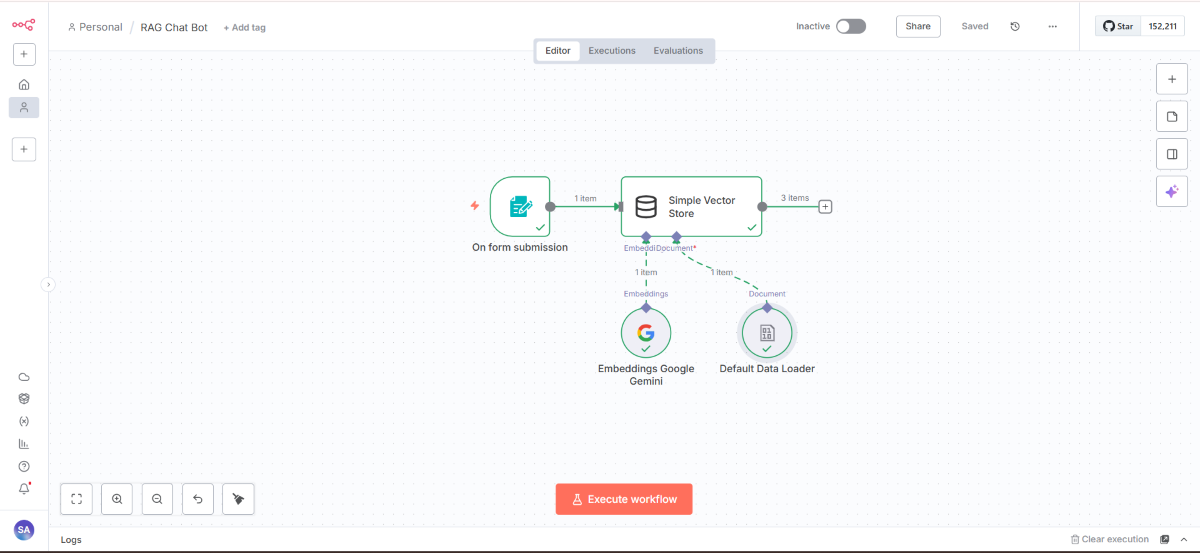
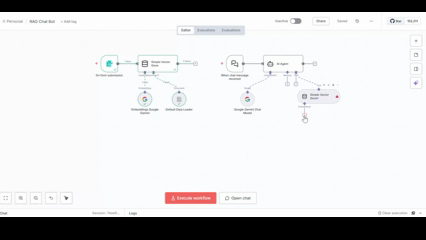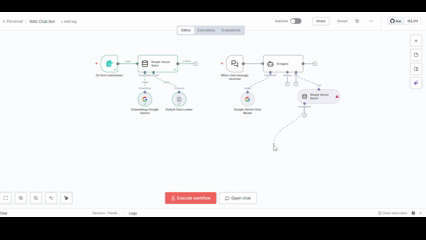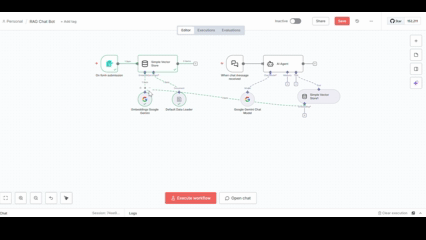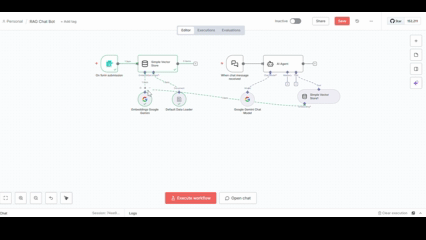
完成するRAGチャットボットのワークフロー
このワークフローは大きく2つの部分から構成されます。
n8nには2つの利用方法がありますが、本記事では初心者の方でもすぐに始められるクラウド版を使用します。
利用方法 | 特徴 | おすすめ度 | 月額費用 |
|---|---|---|---|
クラウド版 | • ブラウザからすぐに利用可能• インストール不要• サーバー管理不要• 自動バックアップ | ★★★(初心者向け) | 無料〜(5ワークフローまで) |
セルフホスト版※ | • 自分のPCやサーバーで運用• 完全無料で利用可能• 高度なカスタマイズが可能• 技術知識が必要 | ★★☆(上級者向け) | 無料(サーバー代は別途) |
※セルフホスト版:クラウドサービスを利用するのではなく、自分でサーバーやインフラを用意し、ソフトウェアやサービスを設置・運用すること。
それでは、実際にシステムを構築していきましょう。
この章では、RAGチャットボット構築に必要な基礎知識と、必要なツールの準備を行います。
まず、RAGがどのように動作するか、簡単に理解しておきましょう。
RAGは以下の3つのステップで動作します。
ステップ | 処理内容 | 具体例 |
|---|---|---|
1. 検索(Retrieval) | 質問に関連する情報を知識ベースから検索 | 「有給休暇」→ 就業規則の該当部分を検索 |
2. 拡張(Augmented) | 検索結果を質問と組み合わせてコンテキスト作成 | 質問+検索結果を組み合わせ |
3. 生成(Generation) | AIが拡張されたコンテキストから回答を生成 | 自然な文章で回答を作成 |
RAGの核心は「ベクターデータベース」にあります。
ベクター化の意味
ベクトル化とは、人間の言葉をAIが理解できる数値表現に変換することです。この数値表現では、似た意味の文章ほど近い数値として扱われます。これにより、従来のキーワード検索ではなく、意味的な検索が可能になります。
簡単な例
例えば、「休暇を取りたい」と「有給申請方法」は、使われている文字は違っても意味が近い質問です。これらをベクトル化すると、近い数値となり、システムは関連性が高いと判断して適切な情報を検索できるようになります。
このRAGチャットボットのシステムは、主に以下のツールで構成されます。
必要なもの | 用途 | 費用 |
|---|---|---|
n8nアカウント | ワークフロー管理プラットフォーム | 無料〜 |
Gemini API | AI処理とベクター化 | 無料枠あり(従量課金) |
PDFサンプル | テスト用ドキュメント | 無料(本記事内で提供) |
ブラウザ | 作業環境 | 無料 |
出典:n8n Plans and Pricing – n8n.io、Gemini Developer API の料金
構築するシステムの技術構成を理解しておきましょう。
コンポーネント | ノード名 | 役割 |
|---|---|---|
データ入力 | n8n Form | ファイルアップロード |
データ処理 | Default Data Loader | PDFからテキスト抽出 |
ベクター化 | Embeddings Google Gemini | テキストを数値化 |
データ保存 | Simple Vector Store(保存用) | ベクターDB |
チャット | Chat Trigger | ユーザーインターフェース |
AI処理 | AI Agent + Gemini Chat Model | 回答生成 |
検索 | Simple Vector Store(検索用) | 知識ベース検索 |
作業を始める前に、以下を確認してください。
AIエンジンとして使用するGoogle Geminiの APIキーを取得します。
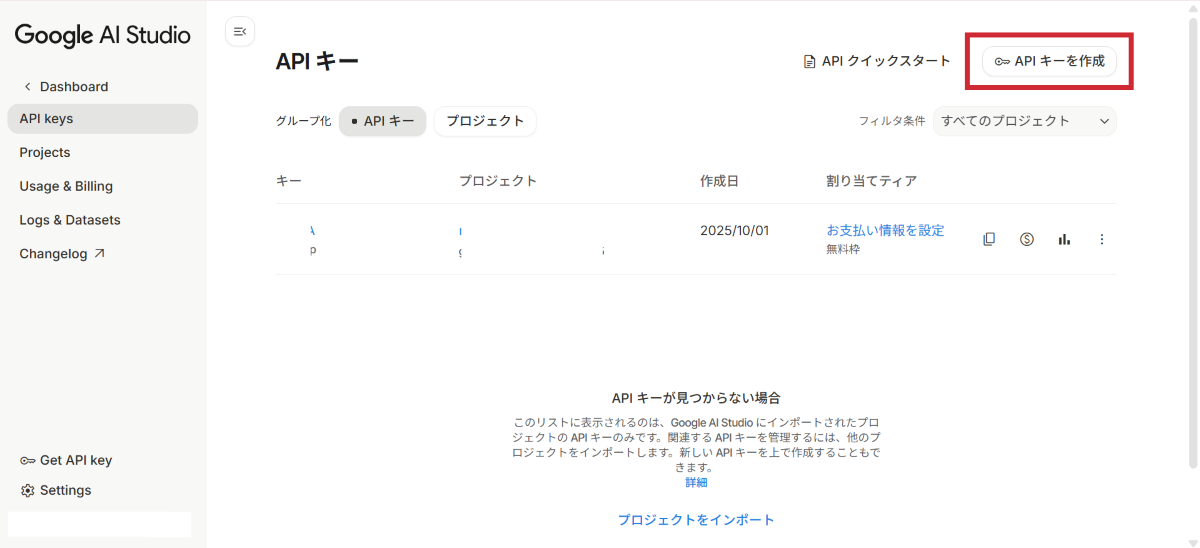
セキュリティ上の注意
テスト用として、架空の就業規則PDFを用意しました。
[ サンプル就業規則PDFをダウンロード]
サンプルに含まれる内容
これで準備は完了です。
次章で実際のシステムを構築していきます。
この章では、実際にn8nでRAGチャットボットのワークフローを構築します。
9つのステップで完成させます。
初期設定:n8nワークスペースの準備
新しいワークフローを作成
最初に、PDFなどのドキュメントをアップロードするためのフォームを作成します。
フォームノードの追加
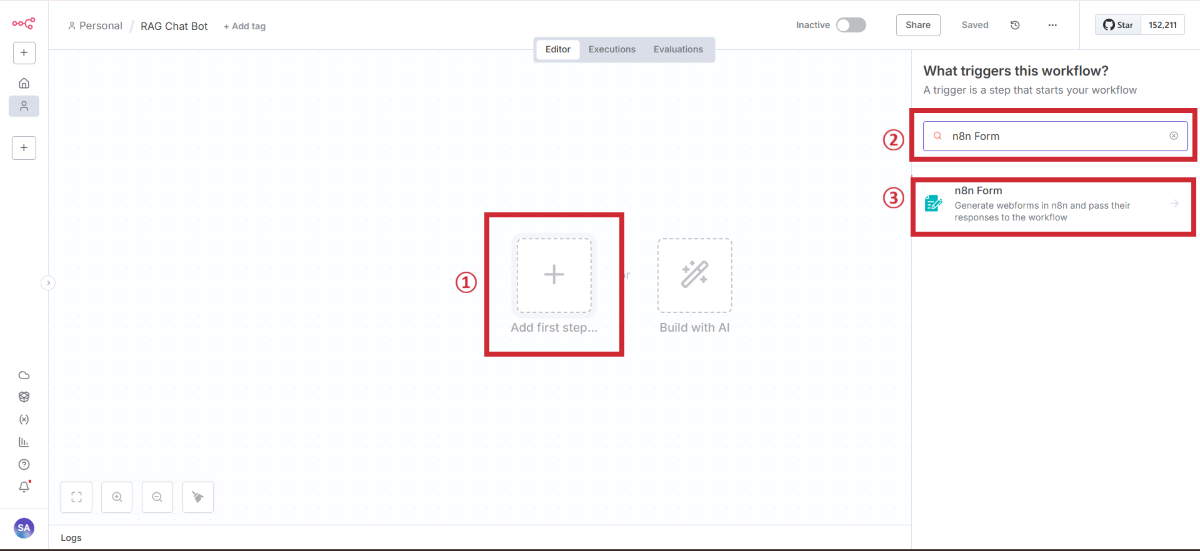
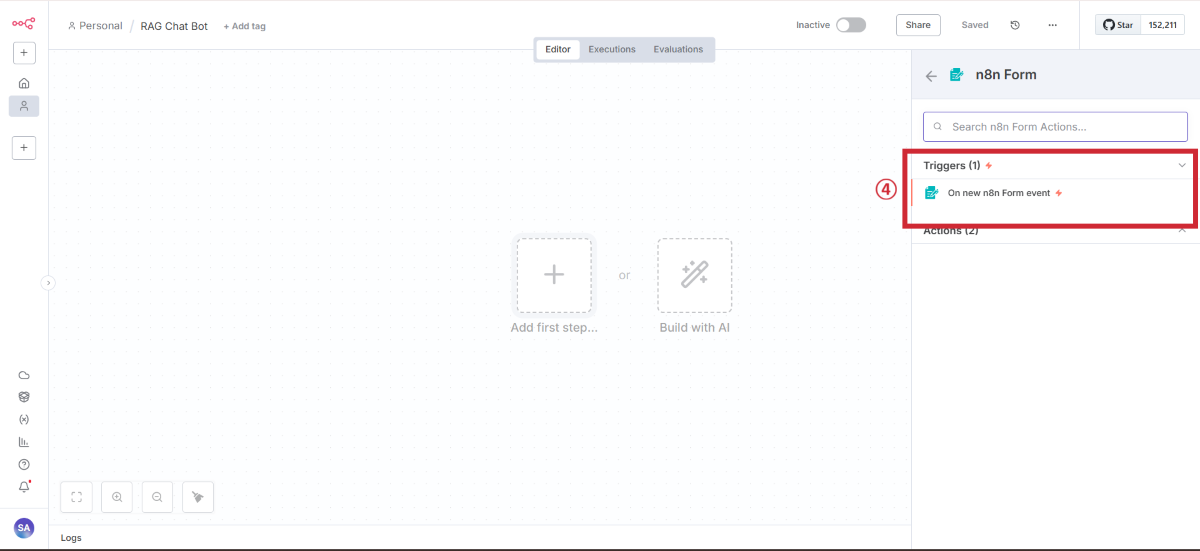
n8n Formノードを追加
フォームの詳細設定
設定項目 | 設定値 | 説明 |
|---|---|---|
Form Title | 保存したいファイルをアップロード | フォームのタイトル |
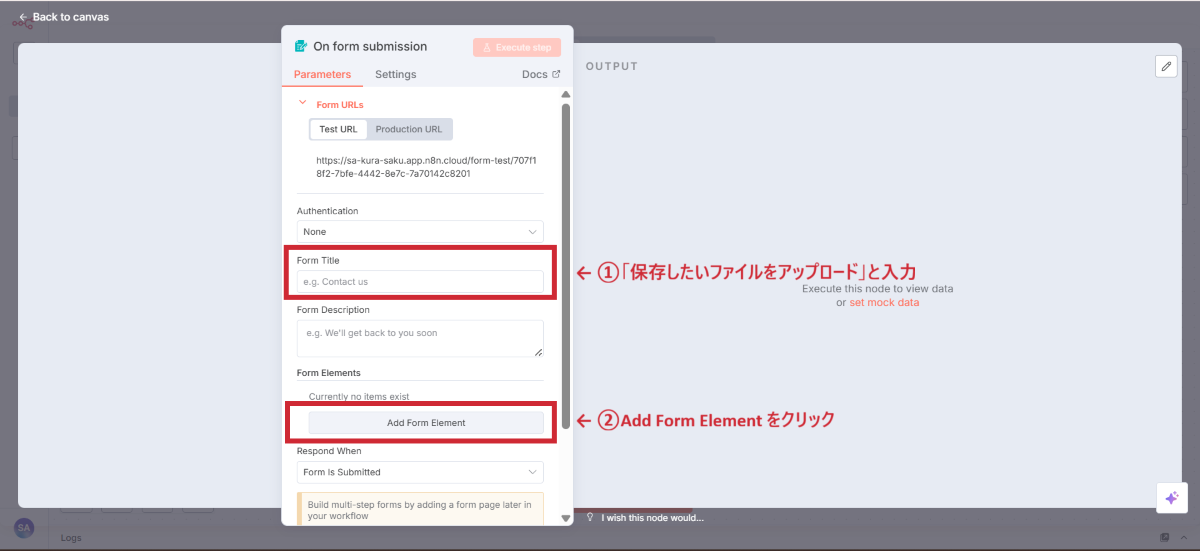
フォーム要素の追加
設定項目 | 設定値 |
|---|---|
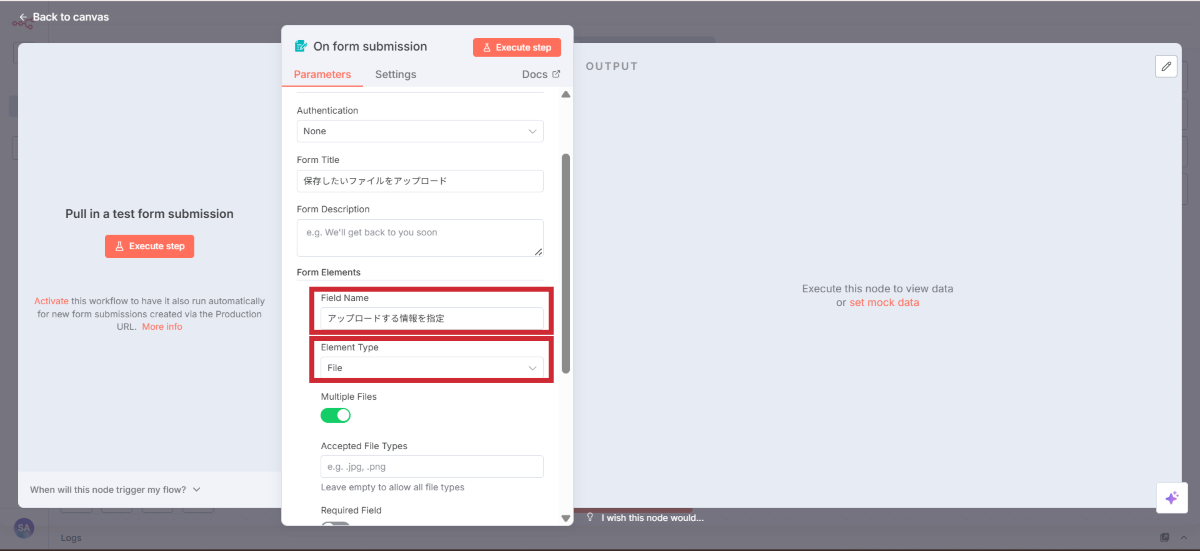
Field Name | アップロードする情報を指定 |
Element Type | File |
アップロードされたデータを保存する「知識ベース」を構築します。
Simple Vector Storeノードの追加
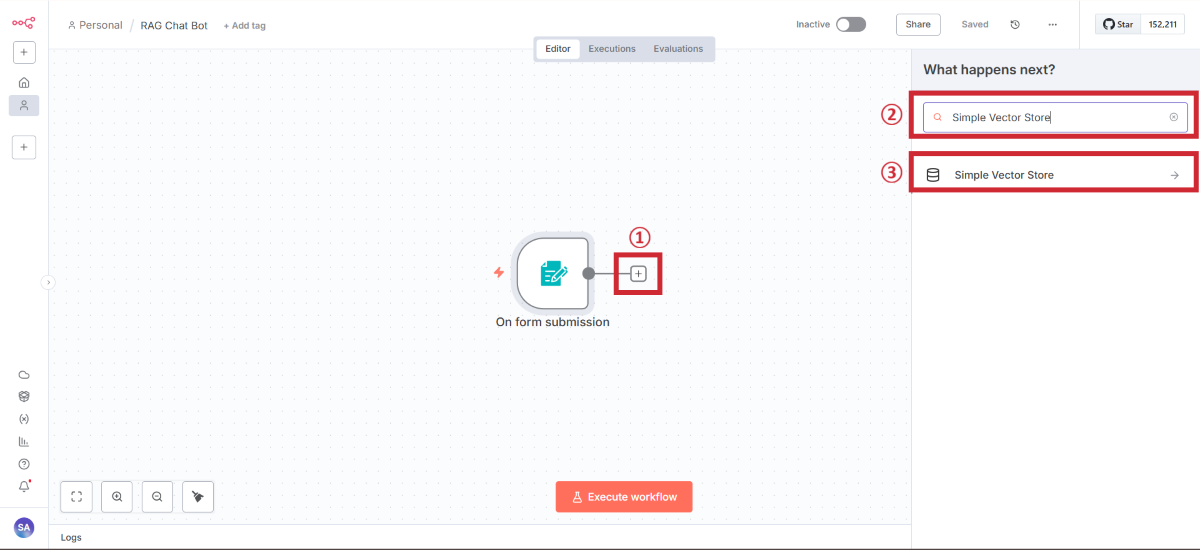
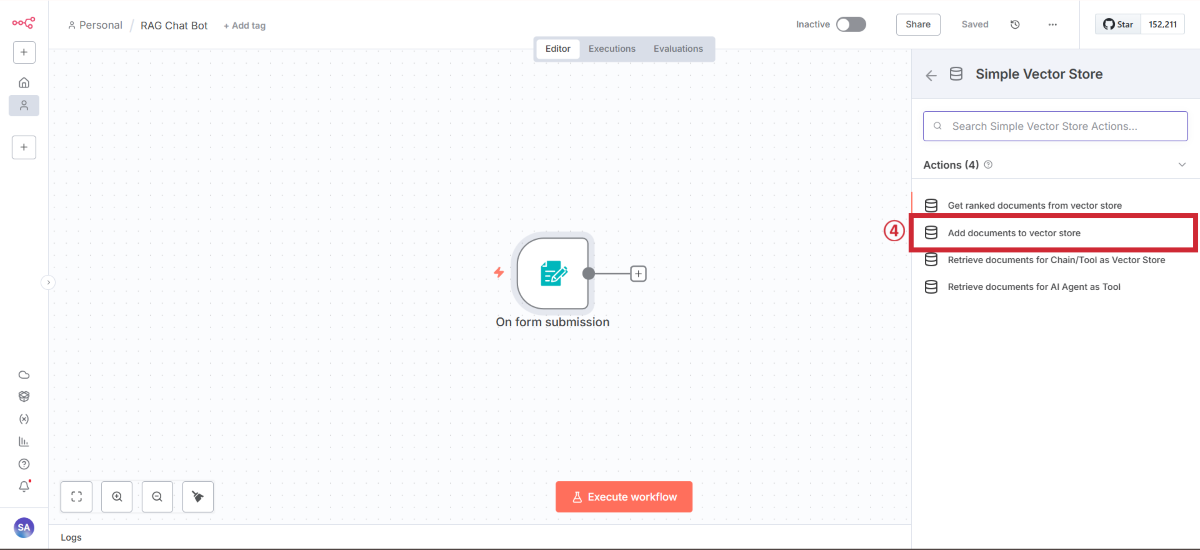
データ保存用のベクターストアを追加
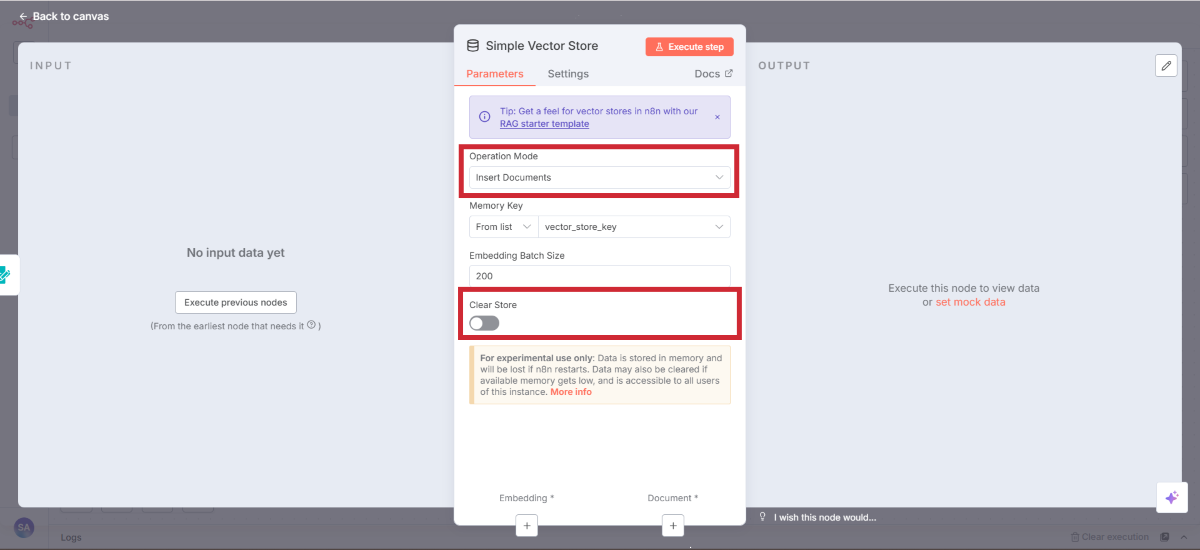
ベクターストアの設定
設定項目 | 設定値 | 説明 |
|---|---|---|
Operation Mode | Insert Documents | データ保存モード |
Clear Store | OFF(通常時) | 既存データを保持 |
Clear Storeについて
PDFなどのファイルから、AIが読めるテキストを抽出します。
Default Data Loaderの追加
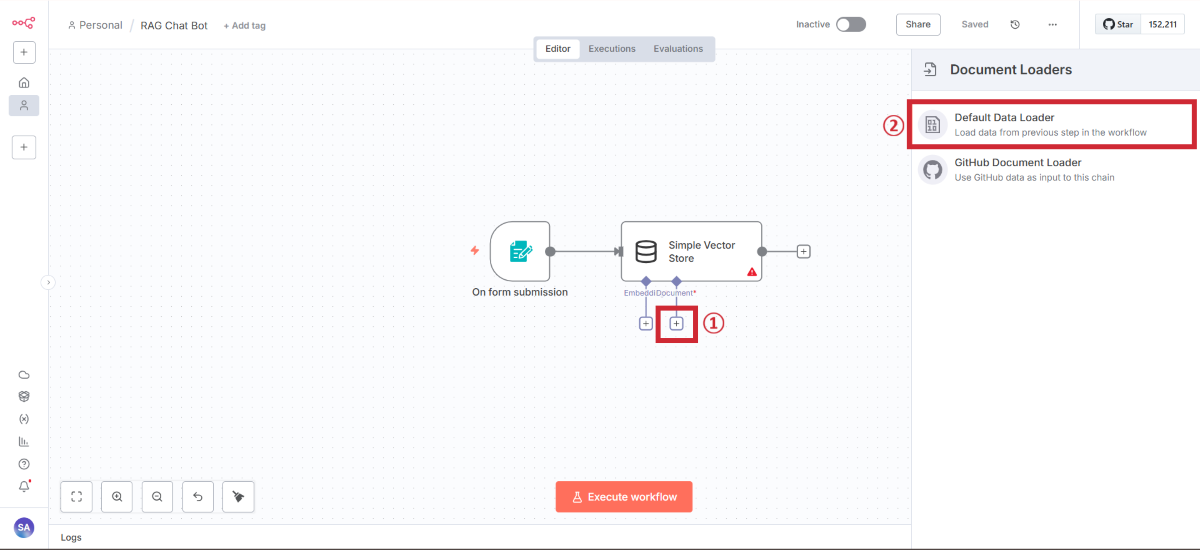
ファイル処理用のローダーを追加
データローダーの設定
設定項目 | 設定値 | 説明 |
|---|---|---|
Type of Data | Binary | バイナリファイル処理 |
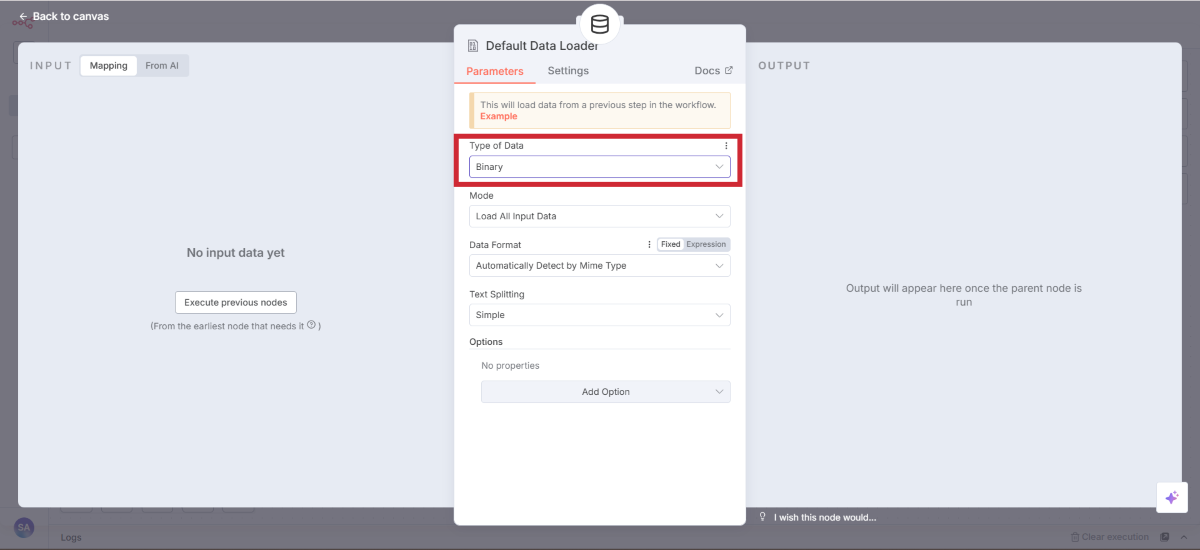
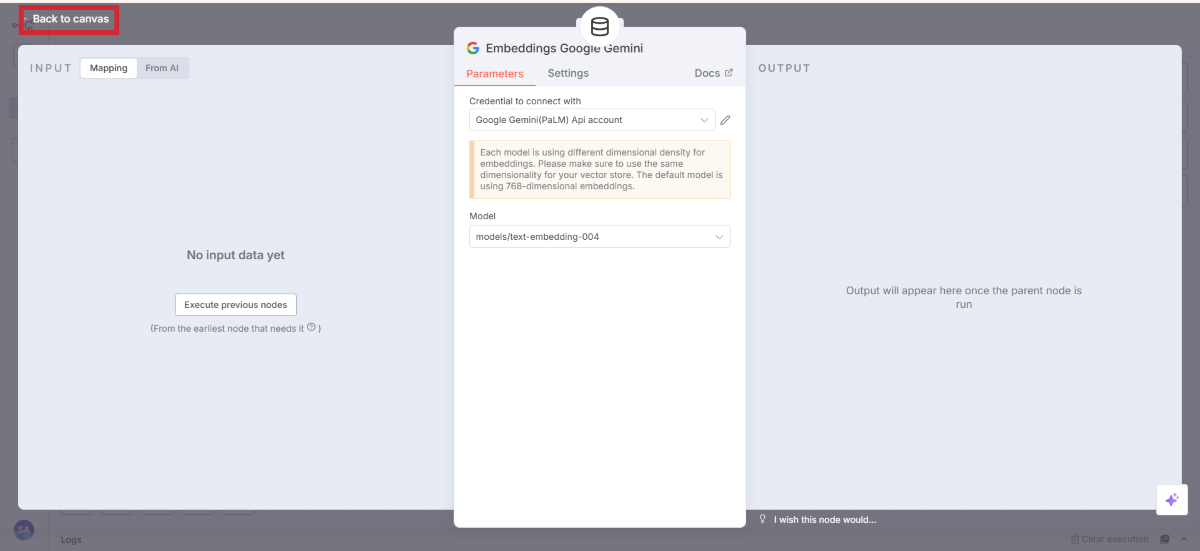
設定できたらBack to canvas でキャンバスに戻りましょう。
抽出したテキストをAIが理解できるベクター形式に変換します。
Embeddings Google Geminiの追加
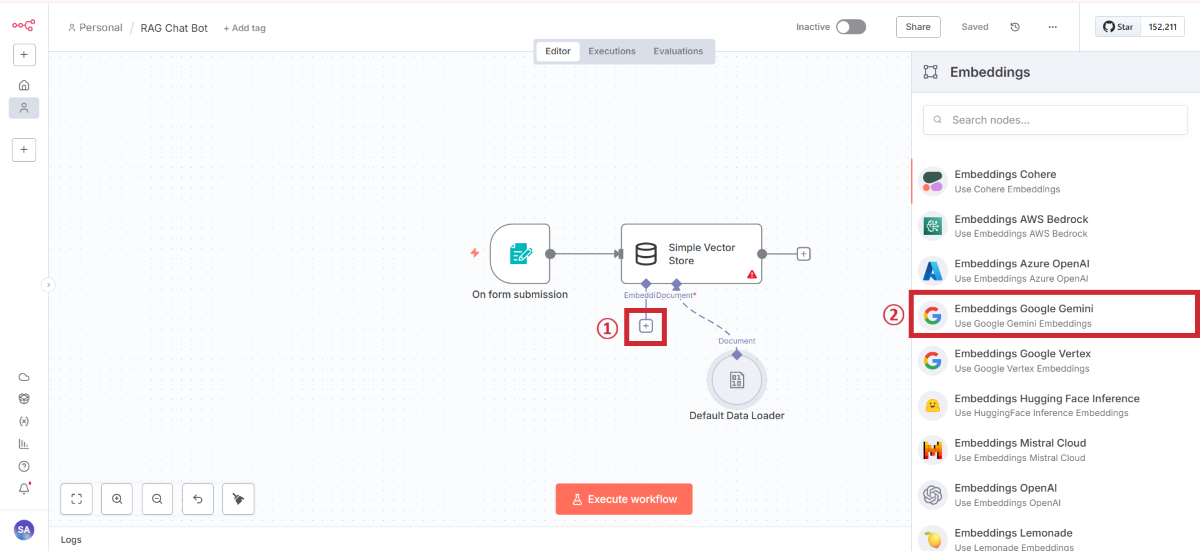
Gemini認証設定
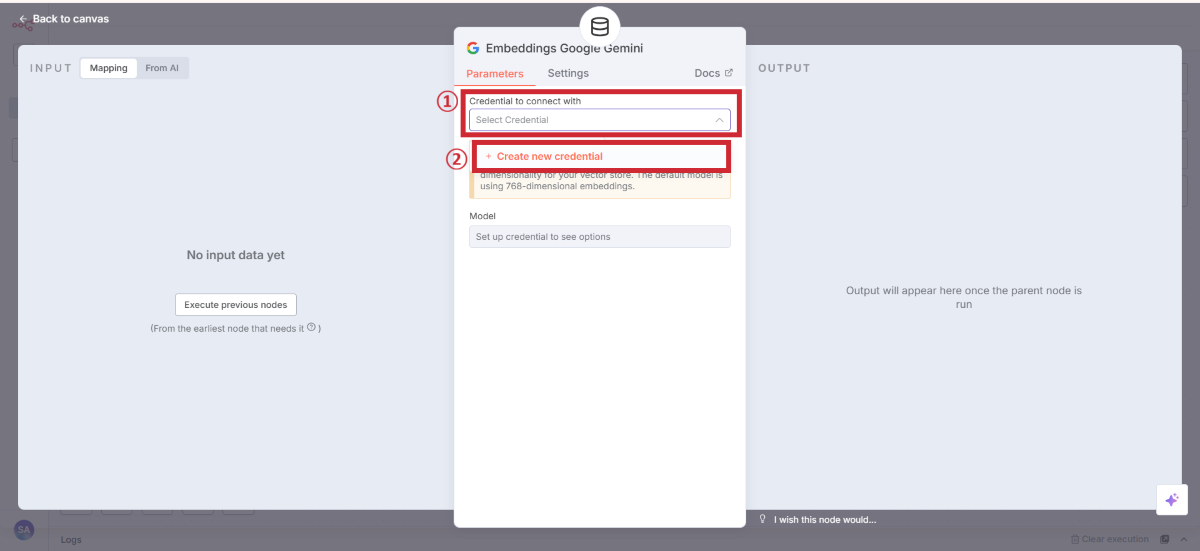
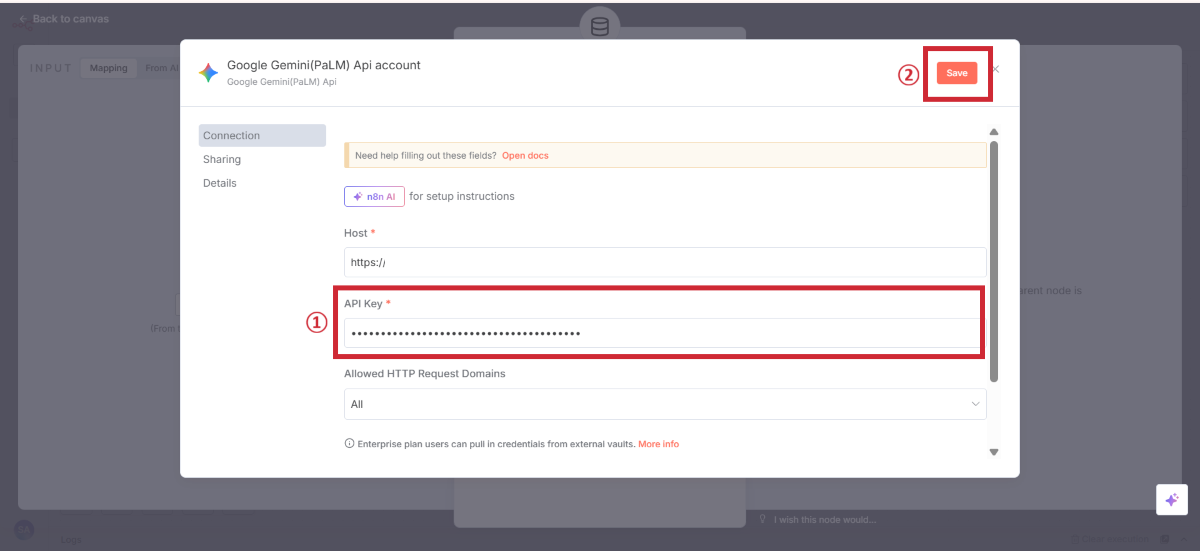
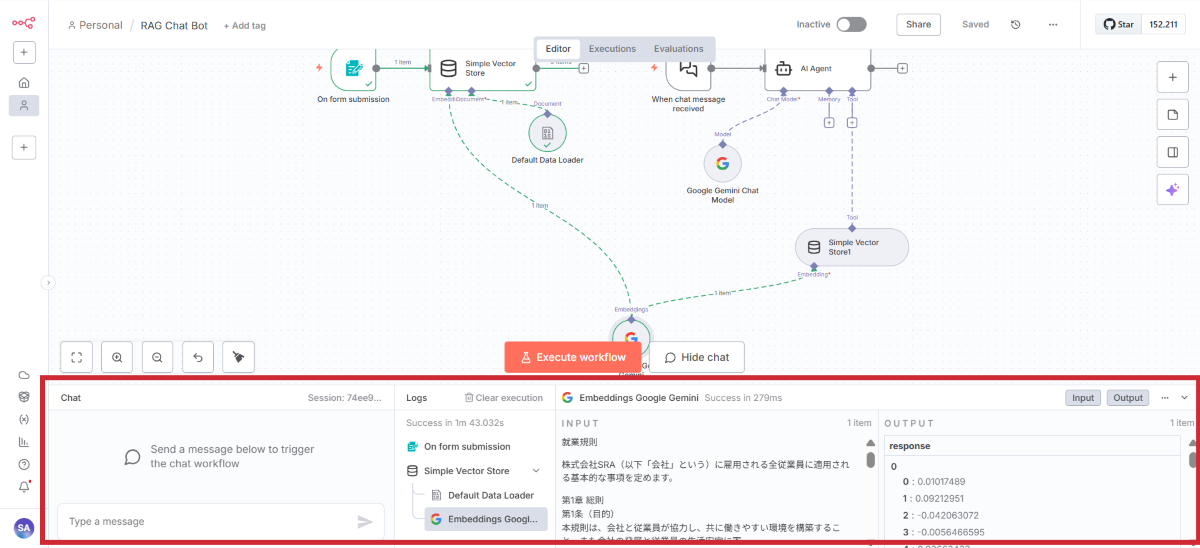
ここで一度、実際にデータをアップロードしてテストします。
データのアップロード手順
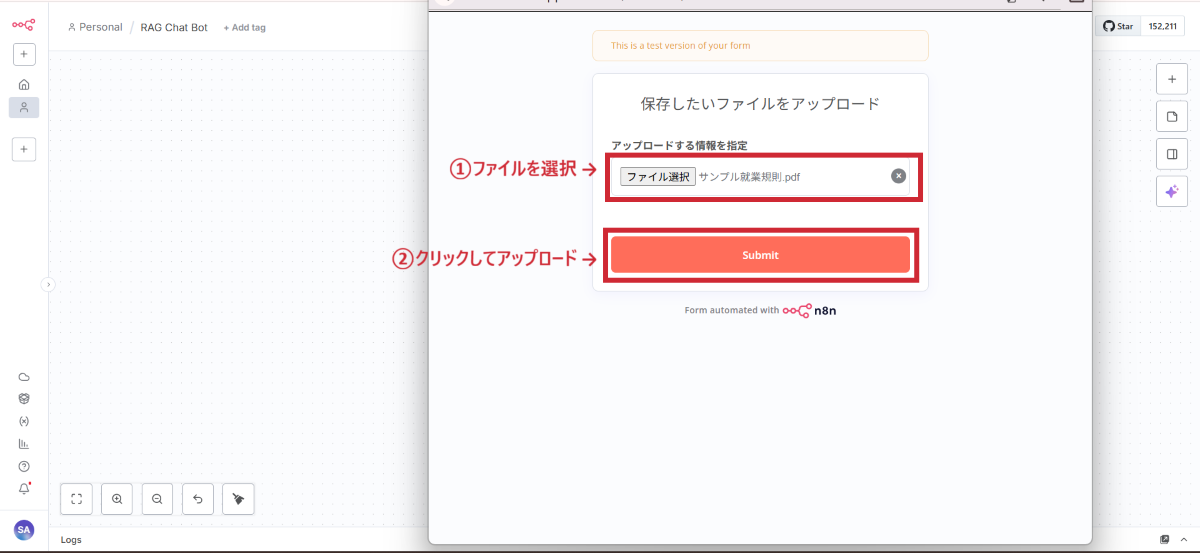
サンプルPDFをアップロード
処理の流れ
アップロード後、以下の処理が自動実行されます。
成功の確認
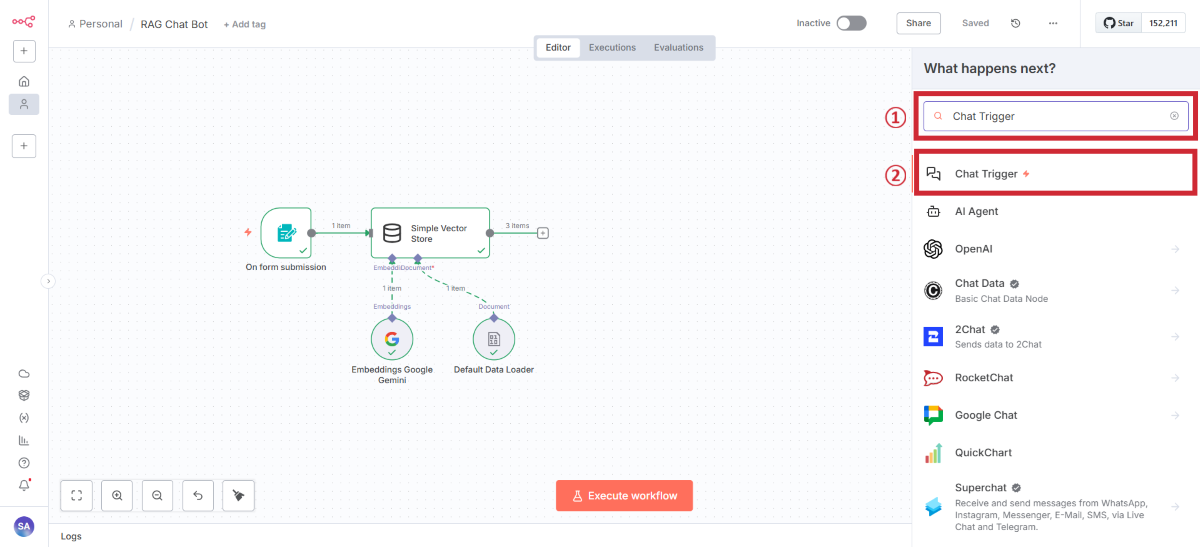
ユーザーが質問を入力するチャット部分を構築します。
Chat Triggerの追加
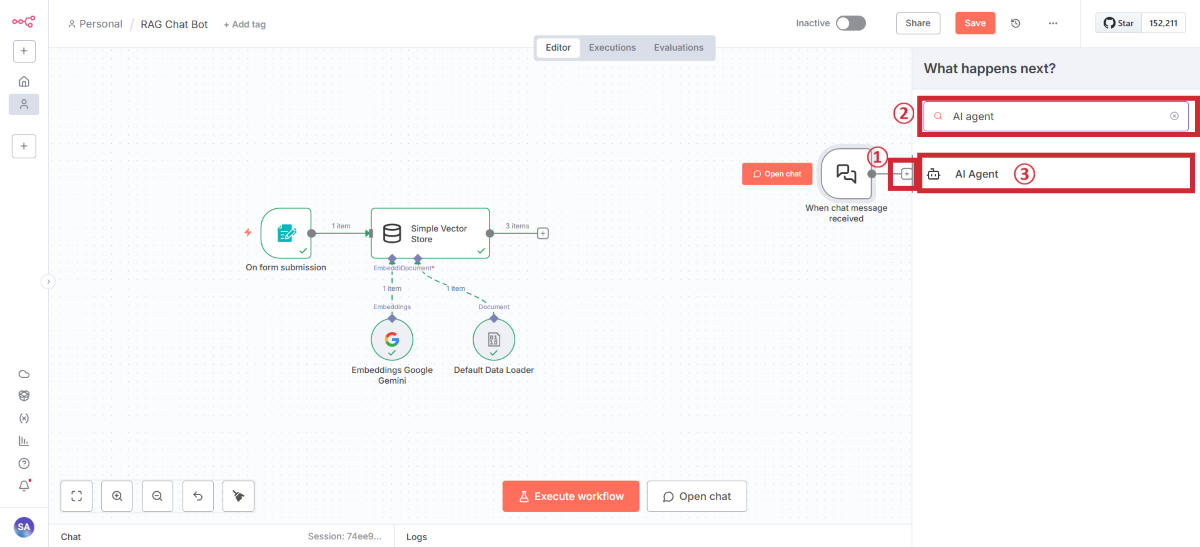
AI Agentの追加
Google Gemini Chat Modelの追加
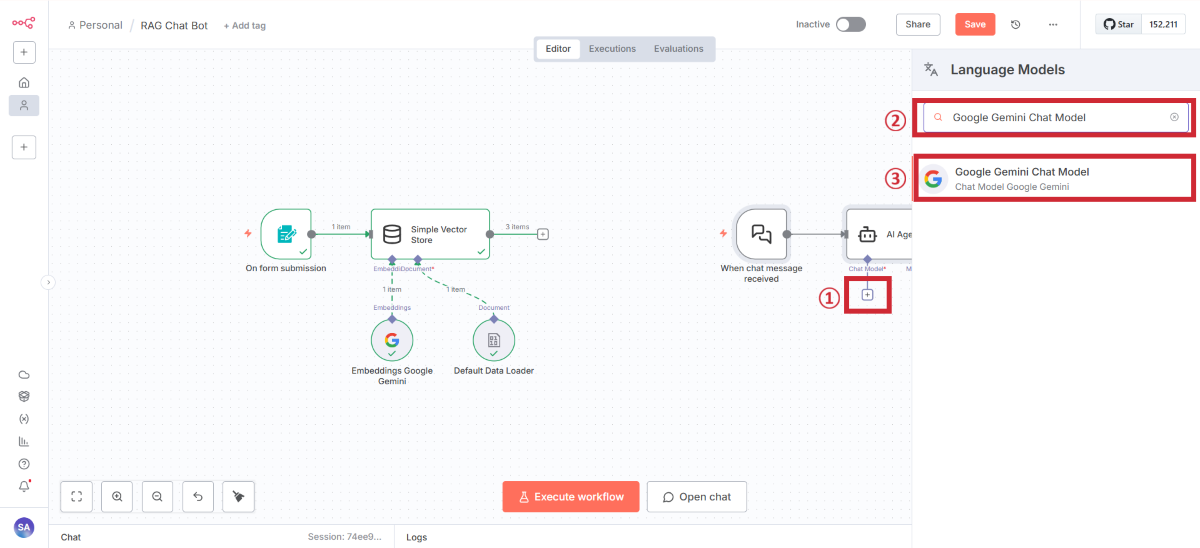
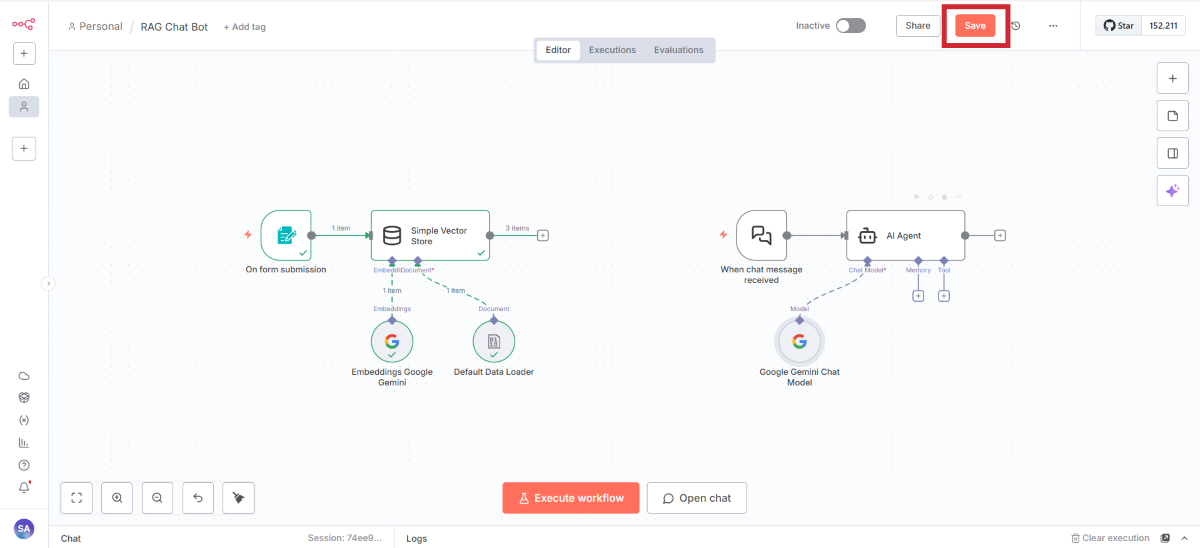
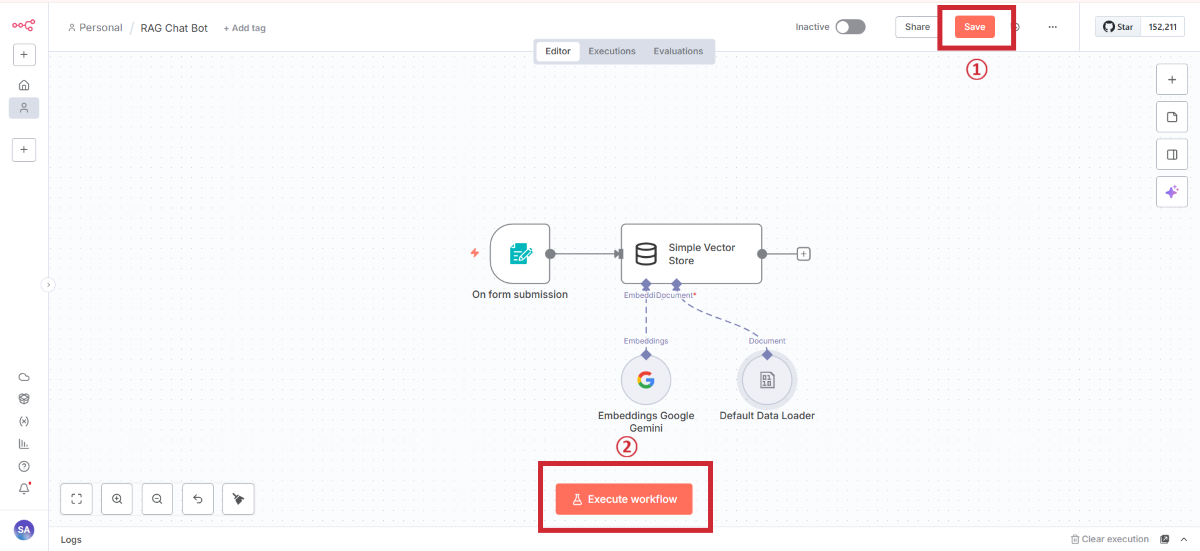
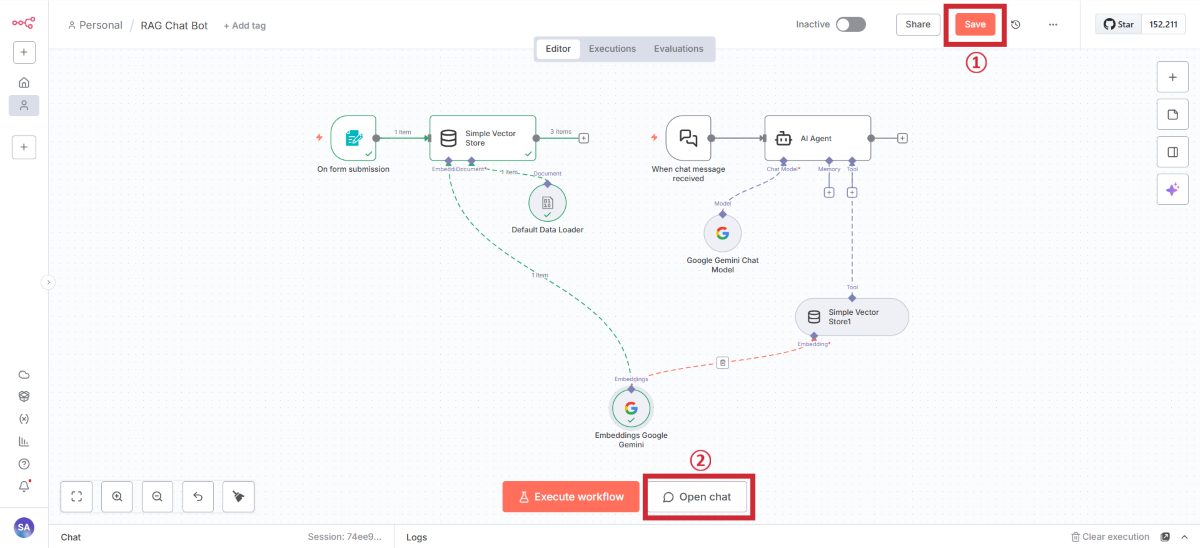
キャンバスに戻ったらSaveしましょう
知識ベースから情報を検索するための設定を行います。
検索用Simple Vector Storeの追加
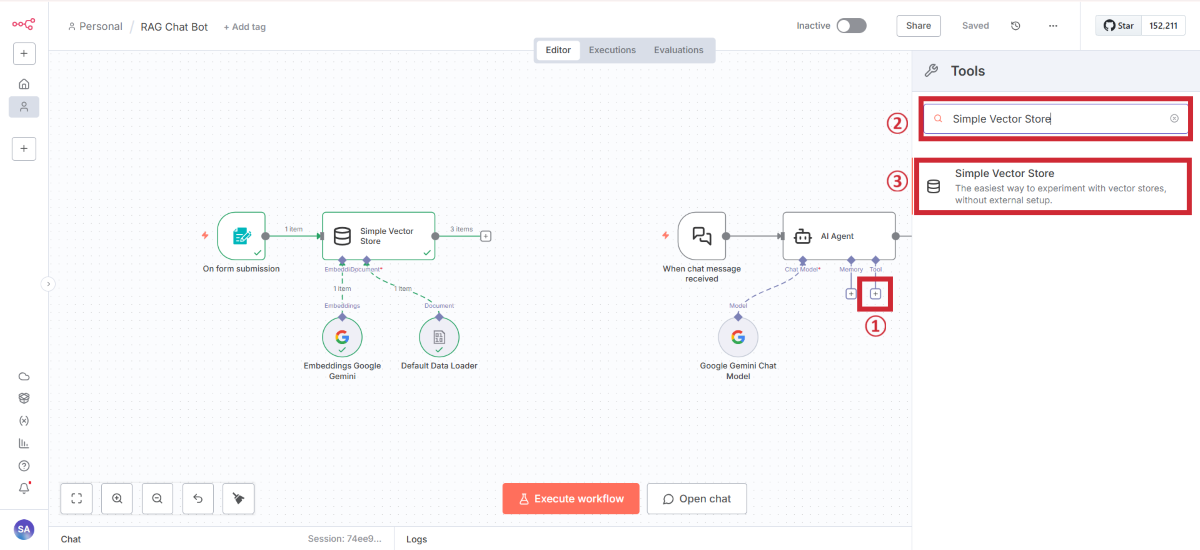
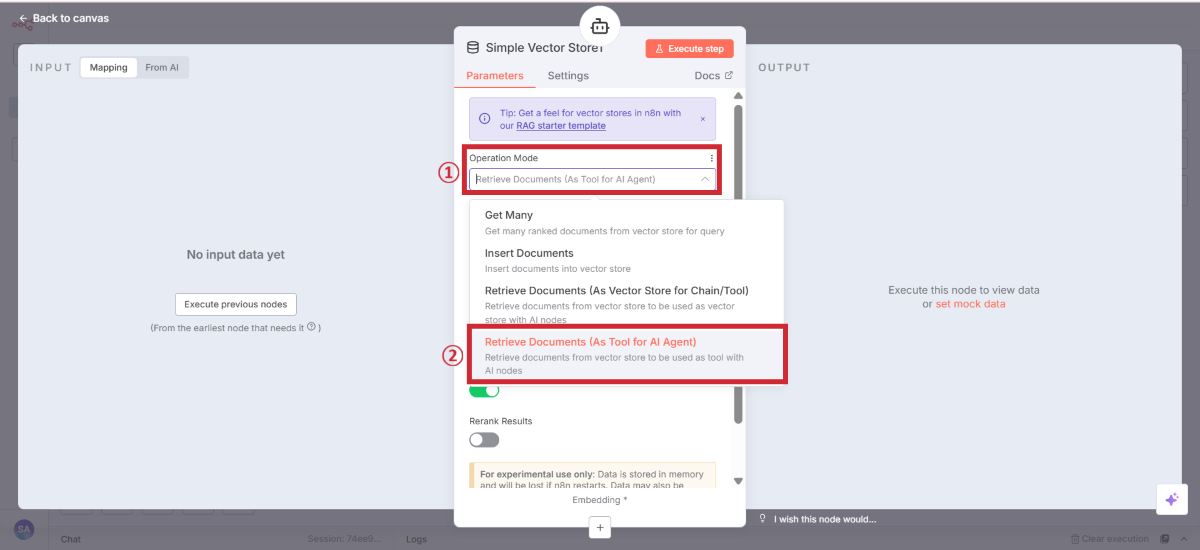
検索用ストアの設定
設定項目 | 設定値 | 説明 |
|---|---|---|
Operation Mode | Retrieve Documents (As Tool for AI Agent) | 検索モード |
Description | 保存されているナレッジを使用して、ユーザーからの質問に回答してください。 | AI向けの説明 |
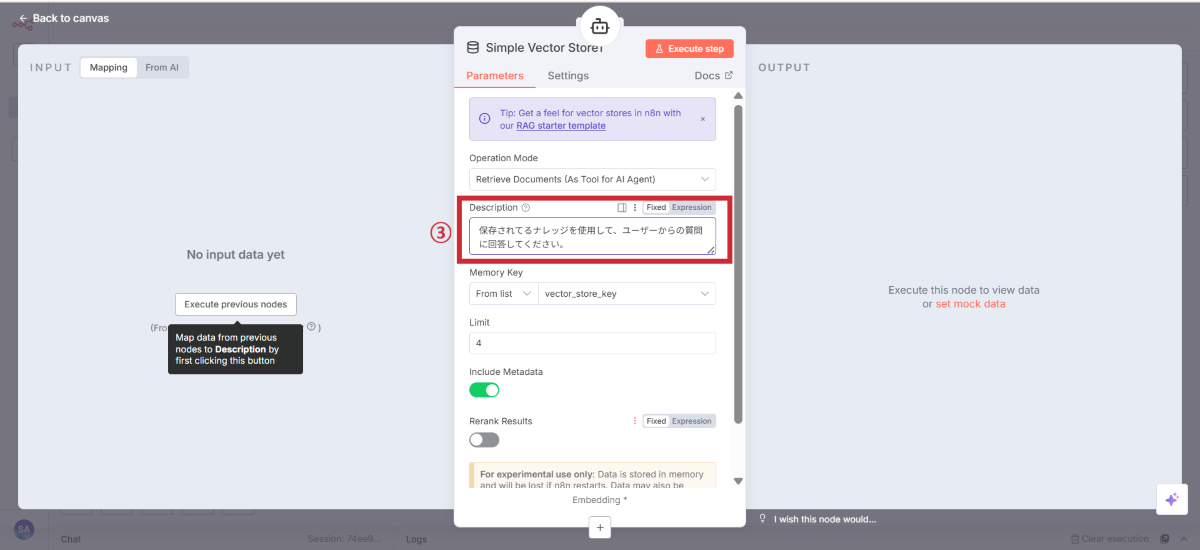
ユーザーの質問をベクター化して、知識ベースと照合できるようにします。
Embeddingの接続
ベクター化ノードを検索処理に接続
接続の意味
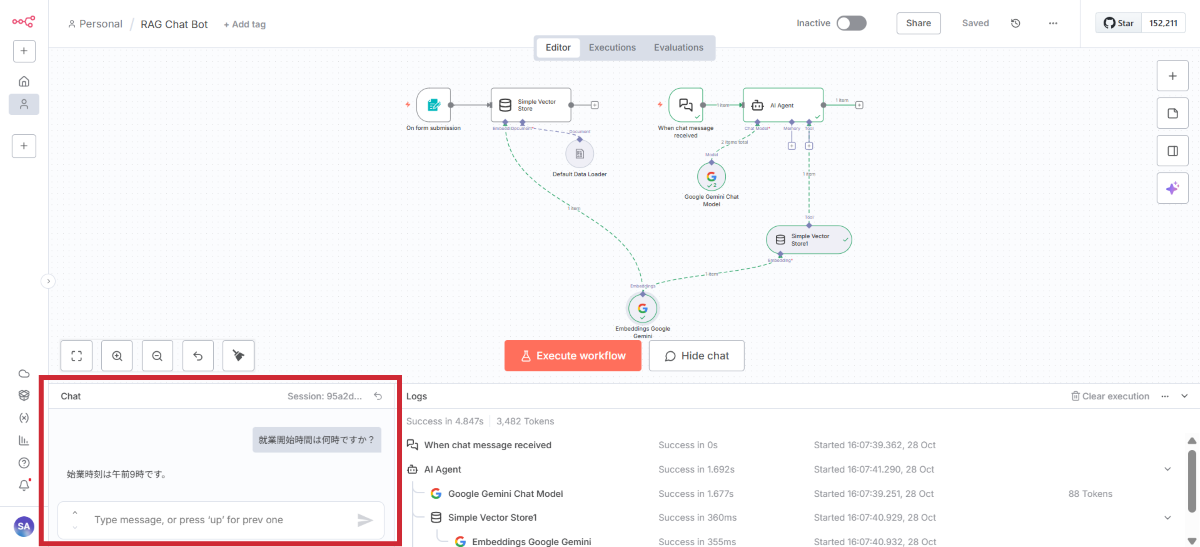
完成したRAGチャットボットをテストします。
チャットの起動
チャットインターフェースが起動
テスト質問の例
アップロードしたドキュメントに基づいて質問してみましょう。
質問例 | 期待される回答 |
|---|---|
「就業時間は何時から何時までですか?」 | 就業規則から勤務時間を回答 |
「有給休暇は何日ありますか?」 | 有給休暇の日数と取得条件 |
「残業手当の計算方法を教えてください」 | 給与規定から残業手当を説明 |
「リモートワークは可能ですか?」 | リモートワーク規定を回答 |
動作確認チェックリスト
基本的なRAGチャットボットが完成したら、実際の業務に合わせてカスタマイズしていきましょう。
システム運用時に発生しやすい問題と対処法をまとめました。
エラー対処表
問題 | 原因 | 解決方法 | 予防策 |
|---|---|---|---|
ファイルがアップロードできない | ファイル形式の問題 | PDFに変換して再試行 | 対応形式を明記 |
回答が的外れ | ベクター化の不一致 | Clean StoreをONにして再登録 | 定期的なメンテナンス |
「情報がありません」ばかり | 検索精度が低い | Top Kを5に増やす | チャンクサイズ調整 |
処理が遅い | データ量が多すぎる | 不要なデータを削除 | データの定期整理 |
文字化けする | エンコーディング問題 | UTF-8で保存し直す | ファイル形式統一 |
同じ回答の繰り返し | キャッシュの問題 | ワークフローを再起動 | 定期的な再起動 |
実際の業務での活用パターンを紹介します。
複数部門の情報を統合管理する拡張
部門 | アップロードする文書 | 想定される質問 |
|---|---|---|
人事部 | 就業規則、評価制度、福利厚生 | 休暇申請、昇進条件 |
経理部 | 経費規定、予算管理、請求書処理 | 経費精算方法、締日 |
IT部 | システムマニュアル、セキュリティポリシー | パスワード変更、VPN設定 |
営業部 | 商品カタログ、価格表、提案書テンプレート | 製品仕様、価格確認 |
実装のポイント
外部向けサポートシステムへの応用
追加設定
設定項目 | 内容 | 効果 |
|---|---|---|
回答トーン | 丁寧でフレンドリー | 顧客満足度向上 |
エスカレーション | 回答不可時は人間へ転送 | 確実なサポート |
ログ記録 | 全質問を記録・分析 | サービス改善 |
営業時間判定 | 時間外は自動応答 | 24時間対応 |
新人研修や社内教育への活用
構成例
RAGチャットボットの導入を成功させるには、「継続的な改善」「組織的な活用」「セキュリティとガバナンス」という3つの要諦が不可欠です 。
まず、継続的な改善においては、導入後のPDCAサイクルを確立することが求められます。
具体的には、単なるユーザーフィードバックの収集に留まらず、利用ログや応答精度(ホールセネーション率など)を分析するパフォーマンスモニタリングを通じて、システムの課題を定量的に特定します。
この結果に基づき、情報鮮度と関連性を維持するためのデータガバナンスプロセスを策定し、ナレッジベースの定期的な更新を確実に行う必要があります。
次に、システムを組織文化として定着させる組織的な活用が鍵となります。
全社展開にあたっては、単にツールを配布するのではなく、部門別・職種別の体系的なユーザートレーニングとチェンジマネジメントを徹底します。
また、利用を推進する社内チャンピオンを育成し、チャットボットによる業務効率化や意思決定支援といった定量的な成功事例を組織内で積極的に共有・横展開することで、全従業員の利活用を促進します。
最後に、システムの信頼性の根幹となるセキュリティとガバナンスです。
情報漏洩リスクを最小限に抑えるため、ロールベースのアクセス制御(RBAC)を適用し、ユーザーの権限に応じてアクセス可能な情報源を厳格に管理します。
RAGシステムが扱う機密情報に対しては、保存時・利用時の暗号化はもちろん、データマスキングなどの手法を導入します。さらに、内部および外部規制(例:個人情報保護法、GDPRなど)に準拠するための定期的なコンプライアンス監査を実施し、システムの透明性と信頼性を維持することが不可欠です。
RAGシステムは、単なる情報検索ツールから、企業の知的な業務アシスタントへと進化を遂げます。
その発展は、以下の3つのフェーズで計画的に進められます。
現在の導入フェーズでは、社内文書の検索・回答、および基本的なFAQ対応が主な機能です。既存のナレッジベース(ドキュメント、マニュアルなど)をインデックス化し、従業員からの定型的な問い合わせに対して、迅速かつ正確な一次回答を提供することで、サポート部門や事務作業の負荷軽減を実現しています。
この段階では、安定的な動作と初期データの精度向上に焦点を当てています。
次の高度化フェーズでは、RAGシステムの対応範囲と深度を大幅に広げます。
具体的には、社内データだけでなく、CRMやERPなどの外部データベースとのAPI連携を実装し、より実践的な業務情報に基づいた回答を可能にします。
さらに、ユーザーの利用パターンやフィードバックからシステムが自律的に精度を調整する自動学習機能を追加することも可能です。
加えて、テキスト情報だけでなく、設計図や製品動画などに対応するマルチモーダル対応を導入し、多様な情報源からのインサイト抽出を実現します。
最終的なAI統合フェーズでは、RAGシステムは企業のインテリジェンスハブとしての役割を担います。単に過去の情報を参照するだけでなく、市場データや顧客動向を分析し、予測的な情報提供や次にとるべきアクションの提案が可能になります。個々のユーザーの職務、過去の問い合わせ履歴、スキルレベルに基づいて最適化されたパーソナライズド回答を実現できます。
さらに、複雑なビジネスレポートや提案書などの自動文章生成機能を組み込むことで、クリエイティブな業務や高度な意思決定支援に貢献し、組織全体の生産性を飛躍的に向上させます。
RAGチャットボットは、単なる検索ツールではありません。組織の知識を最大限に活用し、情報のサイロ化を解消する強力なツールです。
このシステムを基盤として、さらに高度な知識管理システムへと発展させることで、組織全体の生産性向上と競争力強化を実現できます。
ぜひ、このRAGチャットボットを活用して、あなたの組織の知識管理を次のレベルへ引き上げてください。
—
参考リソース
—
株式会社TWOSTONE&Sonsグループでは
60,000人を超える
人材にご登録いただいており、
ITコンサルタント、エンジニア、マーケターを中心に幅広いご支援が可能です。
豊富な人材データベースと創業から培ってきた豊富な実績で貴社のIT/DX関連の課題を解決いたします。



幅広い支援が可能ですので、
ぜひお気軽にご相談ください!