『n8n×Googleフォーム』スプレッドシート連携によるCSVデータ自動処理システム
全般
2026.01.14


n8nとApifyを連携させ、競合記事の見出し(Hタグ)構成を自動抽出してスプレッドシートに集約する方法を解説します。面倒な手作業を排除し、SEOリサーチの工数を大幅に削減できます。戦略的なコンテンツ企画に集中できる自動化ツール構築ガイドです。

・6万名以上のエンジニアネットワークを活用して課題を解決※
・貴社のDX戦略立案から実行・開発までワンストップで支援可能
※エンジニア数は2026年8月期 第1四半期決算説明資料に基づきます。
SEOやコンテンツ戦略において、競合記事の「Hタグ(見出し)」構成分析は不可欠ですが、従来は手作業で時間と労力がかかっていました。
本記事では、この非効率な作業を解消するため、記事構成の抽出プロセスを「完全自動化」する具体的なツールの構築方法を紹介します。
自動化には、ノーコードツールの「n8n(ワークフロー構築)」と「Apify(ウェブスクレイピング)」を連携させます。この記事を読むことで、見出し構成分析の手作業から解放され、戦略的なコンテンツ企画に集中できるようになります。
使用するツールの概要
ツール | 役割 | 特徴 |
|---|---|---|
n8n | ワークフロー構築 | ノーコードで700以上のサービスと連携可能なオープンソース自動化ツール |
SerpApi | URL取得 | Google検索結果をAPIで取得できるサービス |
Apify | スクレイピング | Webサイトから情報を自動抽出できるクラウドプラットフォーム |
Google Sheets | データ保存 | 取得したデータを一覧で管理 |
出典: n8n Integrations
手作業では不可能な「高速リサーチ」
最大の特徴は圧倒的な時間短縮です。通常、1記事の構成を調べるのに手作業だと3〜5分かかりますが、このツールなら10記事分をわずか数十秒〜数分で取得できます。URLを一つひとつ開いてコピペする単純作業から解放され、空いた時間を「どういう記事を書くか?」という企画・戦略などのクリエイティブな業務に充てられるようになります。
SEOに強い「構造化データ」の取得
単に本文をコピーするのではなく、Apifyのスクレイピング力を使うことで、以下のようなSEO分析に必須の要素をピンポイントで抜き出せます。
取得データ | 説明 |
|---|---|
タイトル(Title) | 検索結果でクリックされるための工夫が凝らされた要素 |
ディスクリプション(Description) | 記事の要約文 |
見出し構成(H1, H2, H3) | 記事の論理展開や骨子 |
「上位表示されている記事が、どういうH2タグの順番で書かれているか」を一目で比較できるリストが自動で生成されるため、勝てる記事構成を練るための有効な材料になります。
完全自動化と高い拡張性
一度n8nでフローを組んでしまえば、あとは「検索キーワード」を変えるだけで、何度でも、どんなジャンルでも使い回すことができます。さらに、n8nの特徴を活かせば、「取得したHタグ構成をChatGPTに入力して、自動で構成案を作成させる」といった、さらに高度な自動化へ発展させることも可能です。
このワークフローは、以下の4つのステップで市場調査や競合分析を自動化します。
まず、n8n上で調査の起点となる「検索キーワード」と、分析対象としたい「記事数(リサーチしたい件数)」を具体的に指定します。
設定した条件に基づいてGoogle検索を自動実行し、検索結果の上位に表示されているWebサイトのURLを抽出し、リスト化します。
取得したURLリストを外部ツール「Apify」と連携させ、各記事から「タイトル」「メタディスクリプション(概要説明)」「Hタグ(見出し構成)」などの構成要素を自動的に抜き出します。
最後に、抽出したすべてのデータをGoogleスプレッドシートへ自動的に書き込み、保存します。これにより、手動でのコピペ作業なしに分析用リストが完成します。
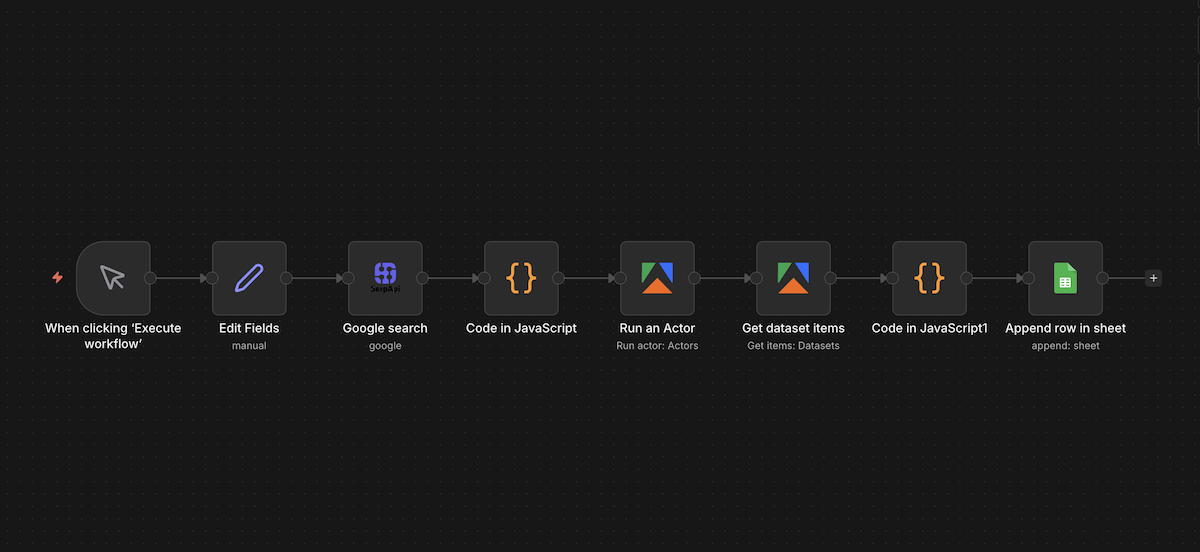
n8nで構築したワークフローの全体構成
このワークフローを実行すると、以下のように検索エンジンで上位表示されている記事の記事構成がスプレッドシートに書き込まれます。
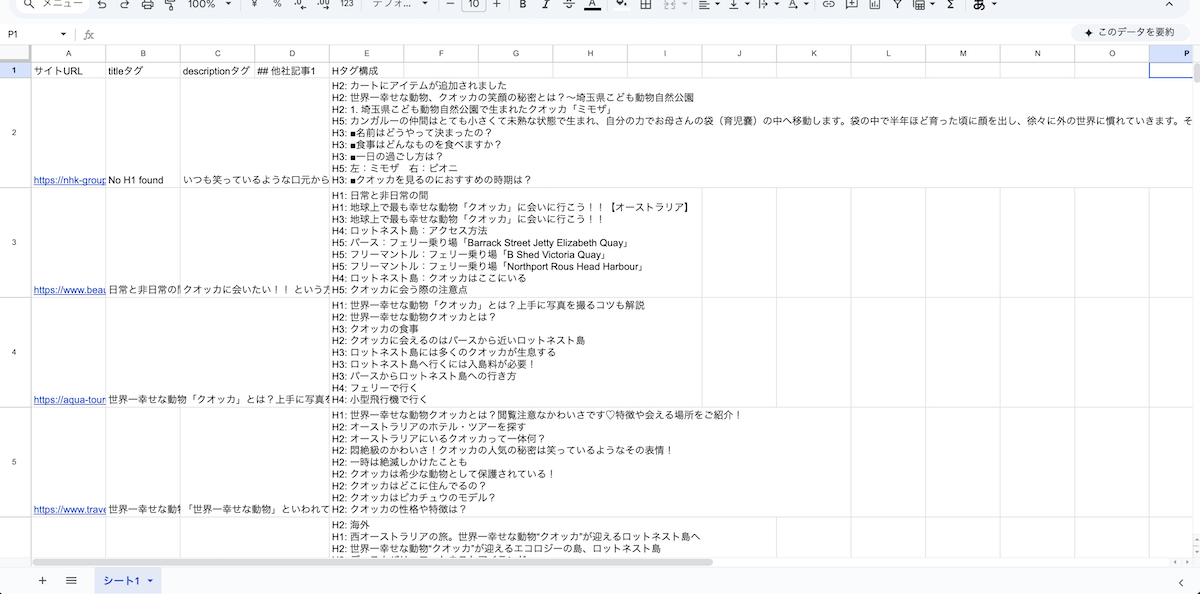
自動で取得された競合記事の構成データ
この章では、ワークフローを構築するために必要なAPIキーの取得とファイルの準備を行います。
なお、本記事では両サービスの無料枠を組み合わせ、コストをかけずにゼロから自動化フローを構築する方法をご説明します。
SerpApiは検索エンジンで上位表示されている記事のURLを取得するために使用します。
以下のURLから無料で取得できます。
取得先
SerpApiはGoogleやBingなどの検索結果をJSONで取得できる便利なツールで、月100回までは無料で利用可能です(クレジットカード登録も不要)。
公式サイトからアカウントを作成し、ダッシュボードに表示される「Private API Key」をコピーしてコードに設定してください。
出典: SerpApi Pricing
Apify API keyはスクレイピングを実行するために使用します。
以下のApify公式サイトから無料会員登録し、取得できます。
取得先
APIキー取得手順
Apifyには「Personal」という無料プランがあり、毎月$5分のプラットフォーム利用クレジット(Compute Units)が自動で付与されます。
今回使用する Cheerio Scraper はブラウザを起動しない軽量なスクレイパーのため消費リソースが少なく、この無料枠だけでも数千〜数万ページの処理が十分に可能です。
出典: Apify Pricing
取得した記事構成を書き込むGoogleスプレッドシートを準備します。
スプレッドシート設定手順
セル位置 | 入力テキスト |
|---|---|
A列1行 | サイトURL |
B列1行 | titleタグ |
C列1行 | descriptionタグ |
D列1行 | ## 他社記事1 |
E列1行 | Hタグ構成 |
スプレッドシートIDの確認方法
書き込み先のスプレッドシートのIDも控えておいてください。
IDはスプレッドシートに表示されるURLを見れば確認できます。
以下のサンプルURLでは、「〇〇」の部分がIDに該当します。
“`
“`

スプレッドシートのヘッダー行設定例
以下のJSONファイルをダウンロードしてください。このファイルには、ワークフローの設定がすべて含まれています。

ダウンロード用のJSONファイル
n8nにログインし、ワークフローをインポートします。
インポート手順
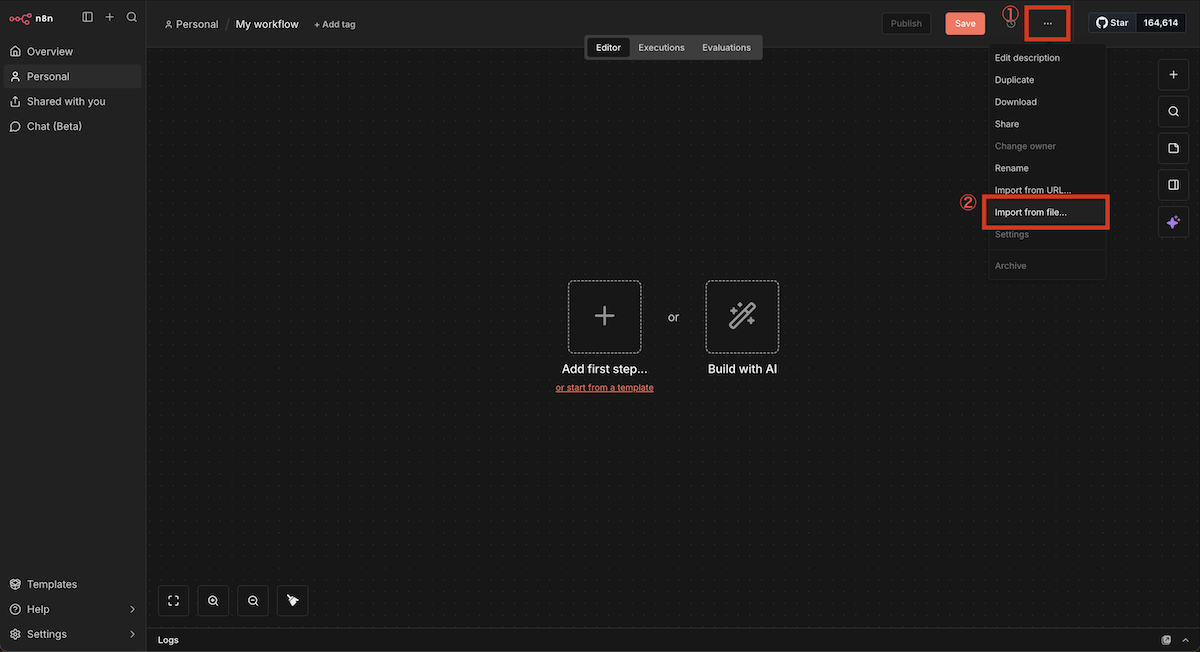
JSONファイルのインポート画面
JSONファイルをインポートすると、以下のようなワークフローが取り込まれます。
JSONファイルをインポートした直後のワークフロー画面
SerpApiとApifyはデフォルトではn8nにインストールされていません
n8nから「SerpApi」と「Apify」をそれぞれノード検索し、「Install node」ボタンをクリックしてインストールしてください。
以上で準備は完了です。
この章では、ワークフローの各ノードを設定していきます。
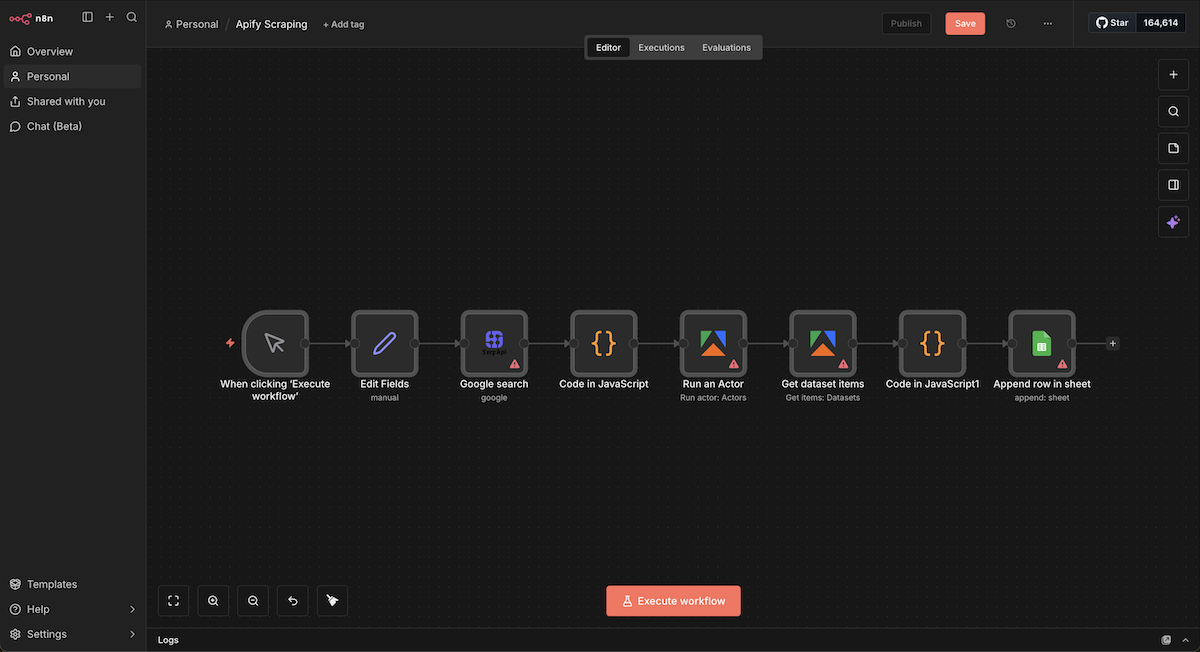
左から2つめの「Edit Fieldsノード」の設定を行います。
※一番左にあるManual Triggerノードはワークフローを手動で開始するためのスイッチのようなものですので、設定不要です。
「Fields to Set」の設定内容
フィールド名 | 型 | 値の例 | 説明 |
|---|---|---|---|
keyword | String | クォッカ 好物 | 記事構成を調査したい検索キーワード |
spreadsheetId | String | (取得したID) | データを書き込むスプレッドシートのID |
numResults | Number | 3 | 取得する記事数(網羅的に調査したい場合は10程度を推奨) |
上記の設定により、「クォッカ 好物」というキーワードで上位表示されている記事3つを取得するという意味になります。
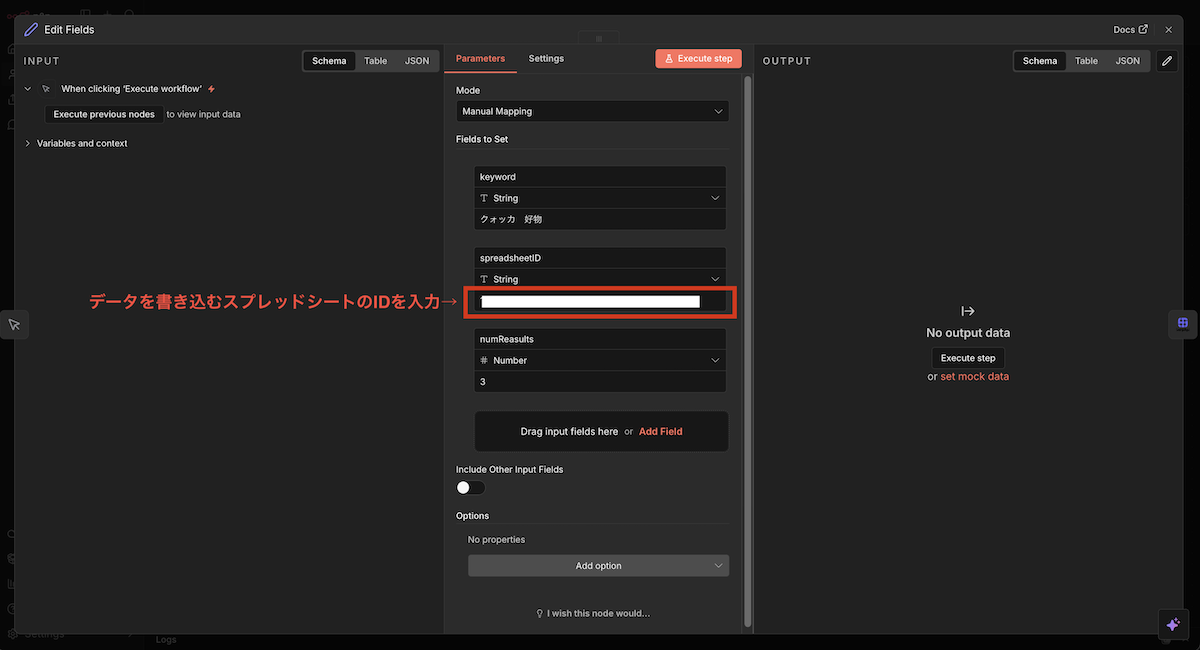
Edit Fieldsノードの設定画面
「Search Query (q)」の右横にあるスイッチをFixed→Expressionに変更し、以下のコードをコピー&ペーストしてください。
“`
{{ $json.keyword }}
“`
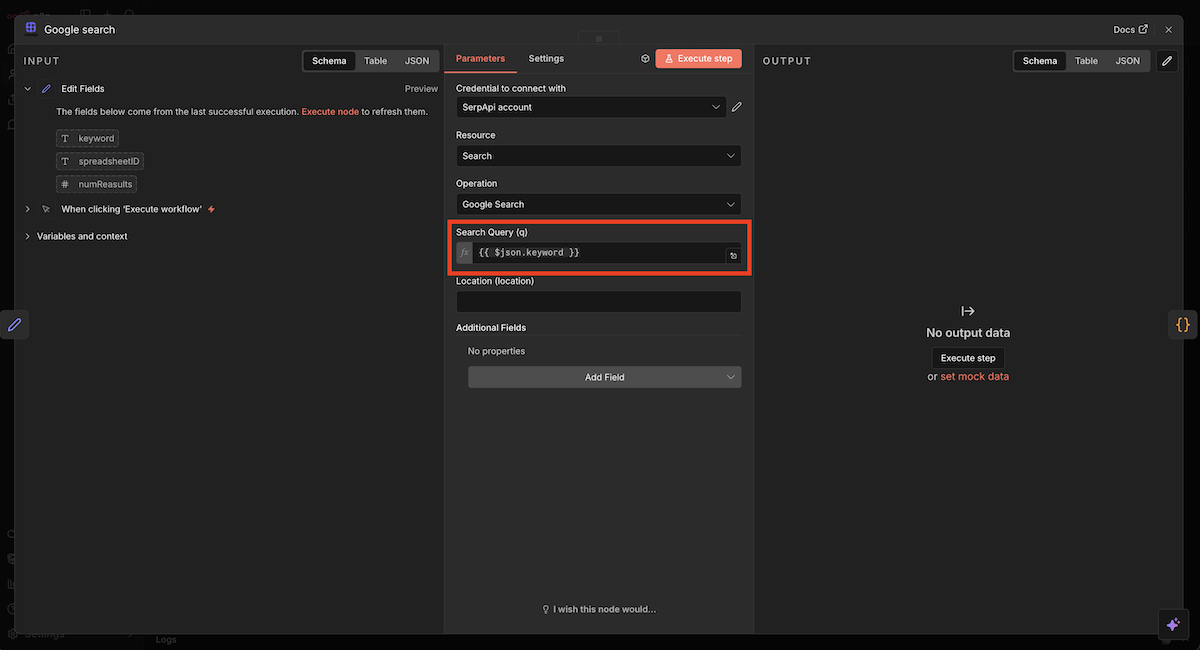
SerpApiノードの設定画面
ノード内に「JavaScript」という項目があるので、以下のコードをコピー&ペーストしてください。
“`javascript
// SerpApiの結果からorganic_resultsを取得
const organicResults = items[0].json.organic_results || [];
// 各結果からURL、title、descriptionを抽出
const processedResults = organicResults.map((result, index) => {
return {
rank: index + 1,
url: result.link || ”,
title: result.title || ”,
description: result.snippet || ”
};
});
// Cheerio Scraper用の完全なInput JSONを作成
const apifyInput = {
startUrls: processedResults.map(result => ({
url: result.url
})),
pageFunction: “async function pageFunction(context) { const { $ } = context; const headings = []; $(‘h1, h2, h3, h4, h5, h6’).each((i, el) => { headings.push({ tag: $(el).prop(‘tagName’).toLowerCase(), text: $(el).text().trim() }); }); const description = $(‘meta[name=\”description\”]’).attr(‘content’) || ”; return { headings: headings, description: description }; }”
};
return [{
apifyInput: apifyInput,
processedResults: processedResults
}];
“`
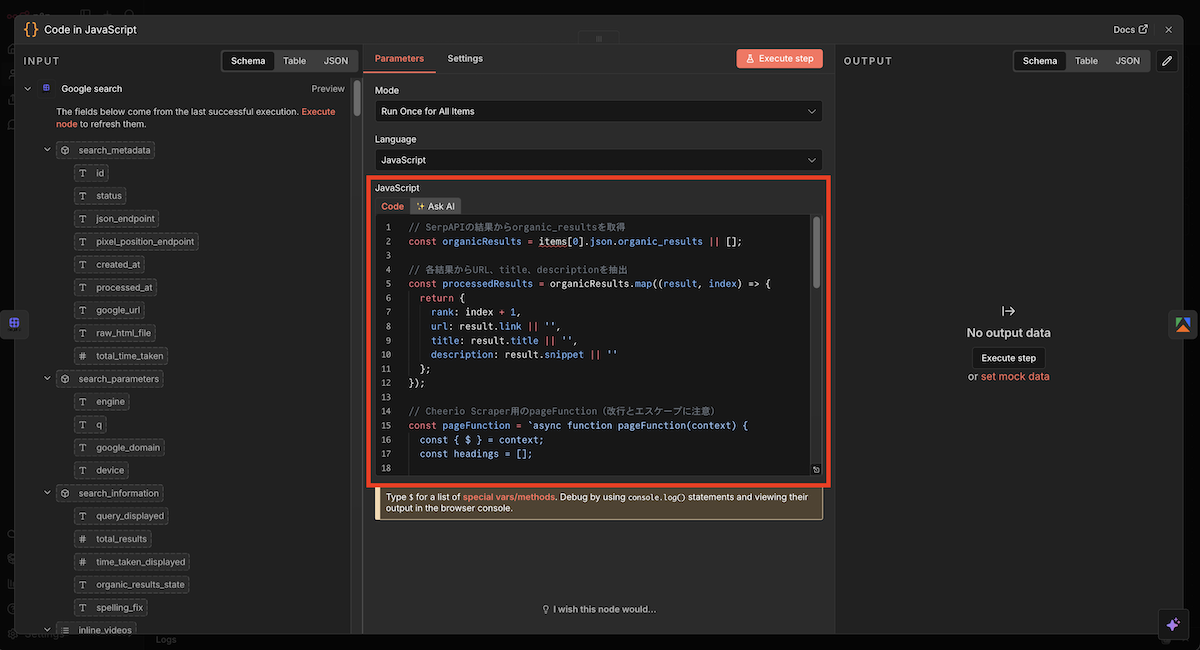
Codeノードの設定画面
Apifyではスクレイピングツールのことを「Actor」と呼びます。
設定手順
設定項目 | 設定値 |
|---|---|
Resource | Actor |
Operation | Run an Actor |
Actor Source | Recently Used Actors |
Actor | Cheerio Scraper (apify/cheerio-scraper) |
Input JSON | {{$json.apifyInput}} |
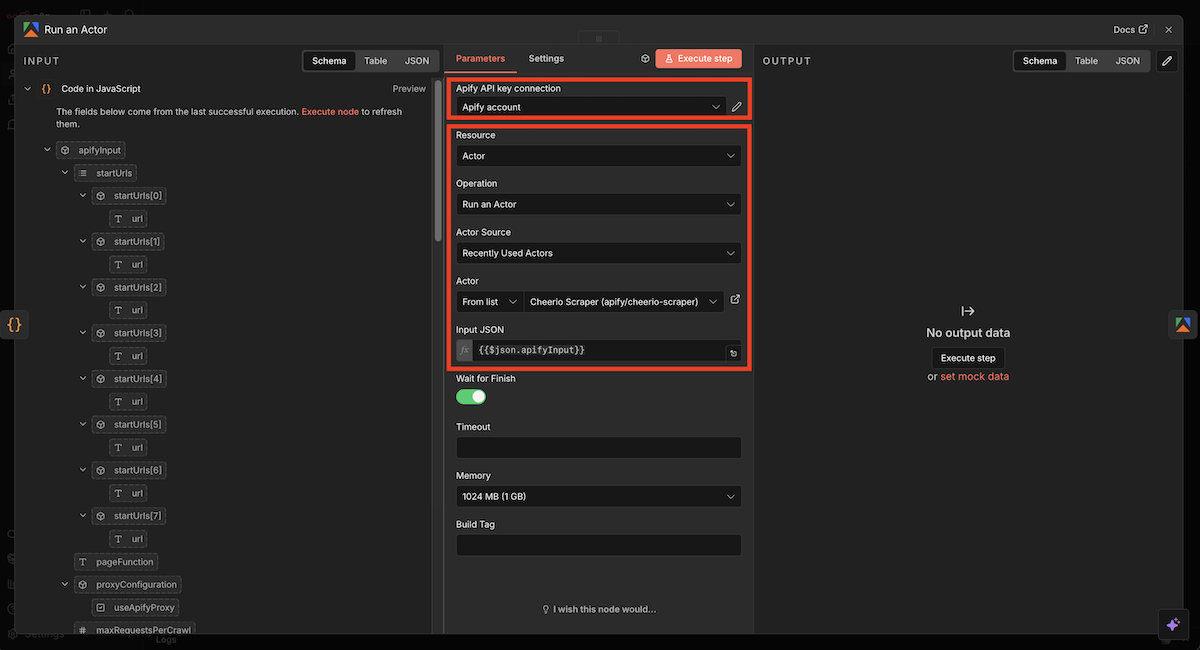
Apify(Run an Actor)ノードの設定画面
ApifyのActorが取得したデータは「Dataset」と呼ばれる格納庫のようなものに保存されます。よって、Get dataset itemsノードでDatasetに格納された情報を引き出します。
Dataset IDの項目右横にあるスイッチをFixed→Expressionに変更し、以下のコードをコピー&ペーストしてください。
“`
{{$json.defaultDatasetId}}
“`
2つのApify関連ワークフローを追加したことにより、検索結果で上位表示されているサイトの記事構成が取得できるようになりました。
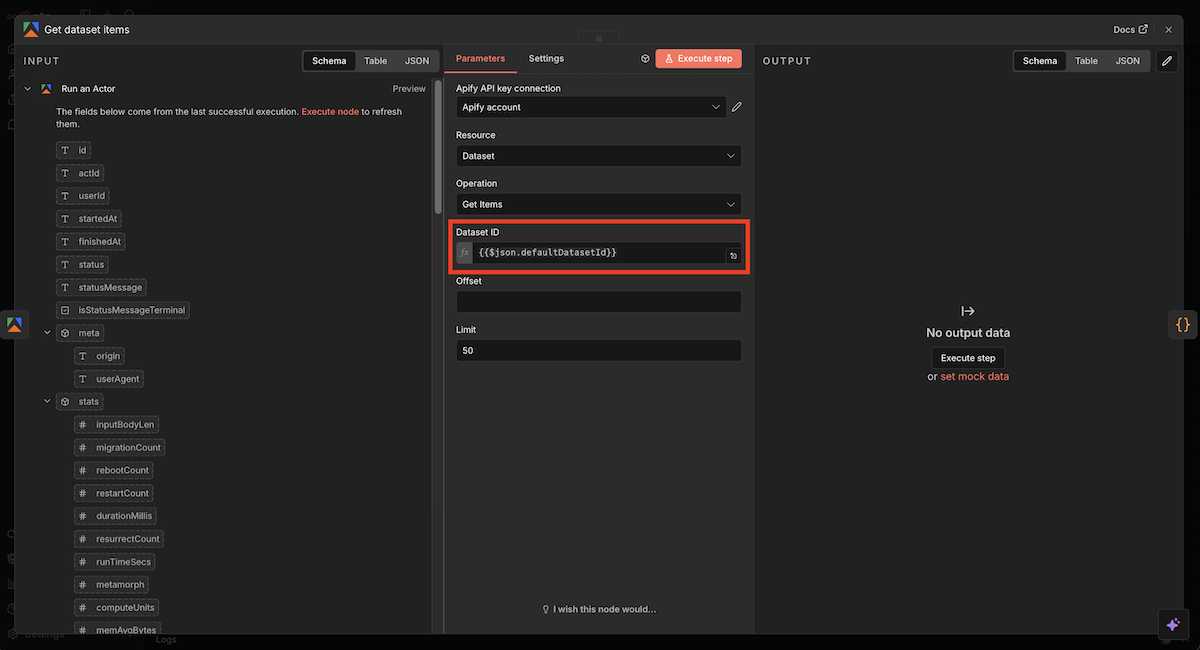
Apify(Get dataset items)ノードの設定画面
Apifyで収集したデータを見やすいように加工します
使用するノードはCodeノードです。
ノード内に「JavaScript」という項目があるので、以下のコードをコピー&ペーストしてください。
“`javascript
// Apify Datasetからの結果を整形
const scrapedData = $input.all();
const sheetsData = scrapedData.map((item, index) => {
const site = item.json;
// Hタグ構成を見やすい形式に変換
const htagStructure = site.headings
.map(h => `${h.tag.toUpperCase()}: ${h.text}`)
.join(‘\n’);
return {
rank: index + 1,
url: site[‘#debug’].url,
title: site.headings.find(h => h.tag === ‘h1’)?.text || ‘No H1 found’,
description: site.description,
htagStructure: htagStructure
};
});
return sheetsData;
“`
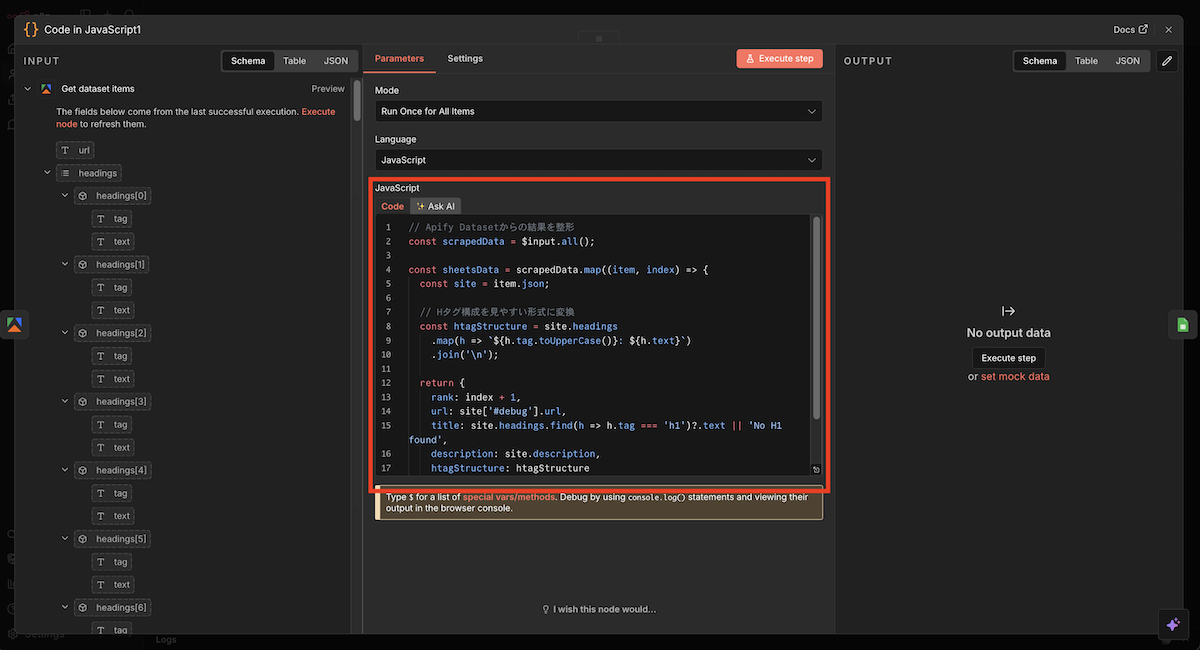
データ加工用Codeノードの設定画面
収集した情報をGoogleスプレッドシートに書き込むための設定を行います。
設定手順
設定項目 | 設定値 |
|---|---|
サイトURL | {{ $json.url }} |
titleタグ | {{ $json.title }} |
descriptionタグ | {{ $json.description }} |
## 他社記事1 | 空欄でOK |
Hタグ構成 | {{ $json.htagStructure }} |
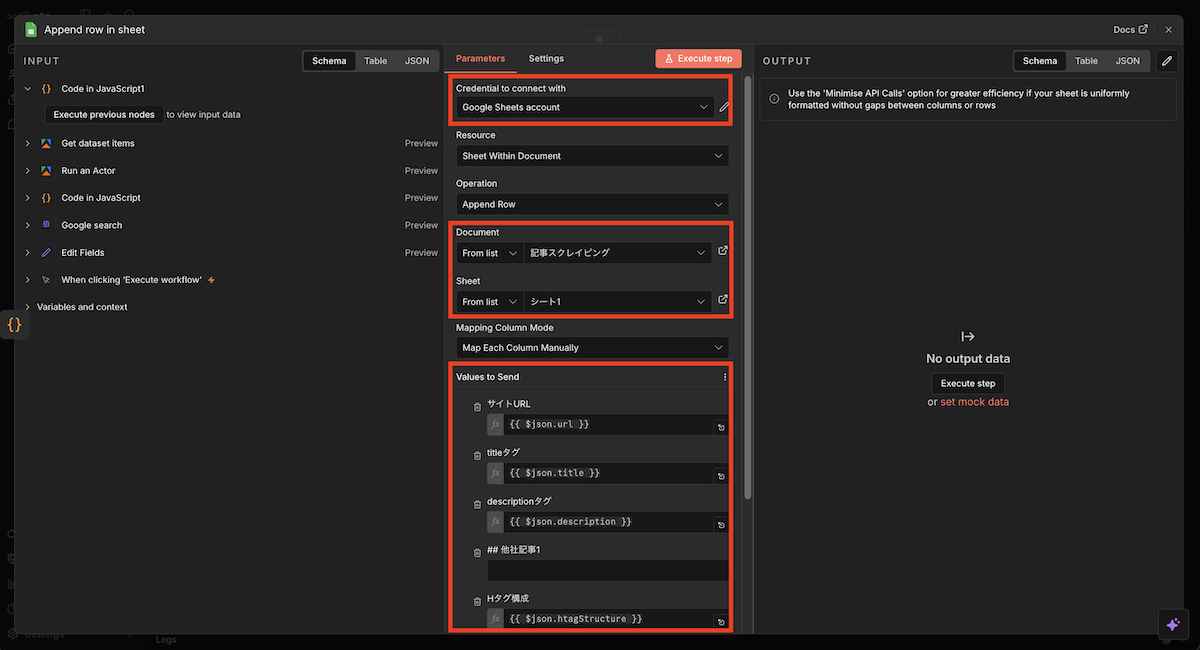
Google Sheetsノードの設定画面
設定が完了したらキャンバスへ戻り、「Execute workflow」をクリックして実行してみてください。
確認項目
□ ワークフロー実行
エラーが発生せず、最後まで正常に実行されること。
□ データ取得
指定した件数分のデータが漏れなく取得されていること。
□ スプレッドシート書き込み
抽出された結果が、連携先のGoogleスプレッドシートに正しく書き込まれていること。
ワークフローが正常に動き、スプレッドシートに結果が書き込まれていれば成功です。
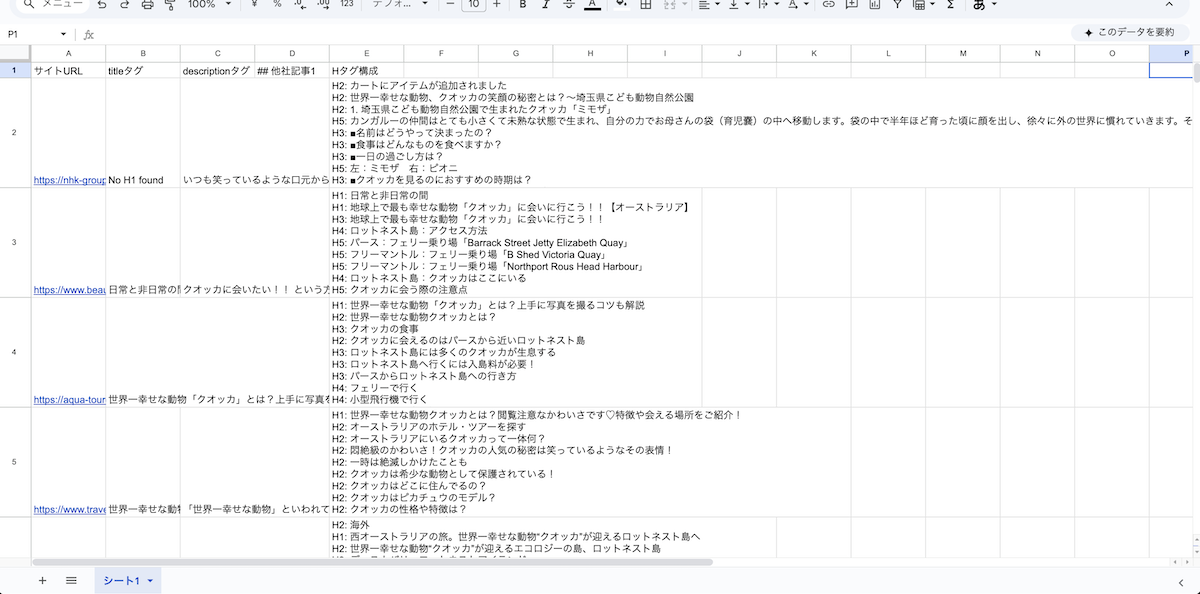
ワークフロー実行後のスプレッドシート
これまで手作業で行っていた情報収集と分析を自動化することで、作業時間を大幅に短縮し、より本質的な「執筆」や「戦略立案」にリソースを集中できるようになります。
このシステムは記事構成の抽出だけでなく、以下のような業務にも応用可能です。
特定の競合サイトを定期的に巡回し、記事の更新状況やページ構成の変更を自動でチェックします。これにより、競合他社の戦略変化をいち早く察知し、自社の対策に活かすことができます。
特定のキーワードで上位表示されている記事の傾向を分析します。どのようなトピックや構成がGoogleに評価されているのかを定量的に把握できるため、SEO対策や市場ニーズの特定に役立ちます。
収集した上位サイトのHタグ(見出し構成)データをAI(LLM)に直接渡すことで、その構成パターンに基づいた新しい記事の構成案を自動生成させることができます。これにより、リサーチから企画立案までの工数を大幅に削減することが可能です。
スクレイピングを起点としたあらゆる業務に活用してみてください。
本記事の作成にあたり、以下の情報を参考にしました。
n8n(ワークフロー自動化)
SerpApi(検索エンジン結果取得)
Apify(ウェブスクレイピング・自動化)
用語解説
用語 | 説明 |
|---|---|
n8n | オープンソースのワークフロー自動化ツール。ノーコードで様々なサービスを連携可能 |
SerpApi | 検索エンジンの結果をAPIで取得できるサービス。Google、Bingなど複数の検索エンジンに対応 |
Apify | Webスクレイピングと自動化のためのクラウドプラットフォーム。6000以上のプリビルトスクレイパー(Actor)を提供 |
Actor | Apifyにおけるスクレイピングプログラムの単位。すぐに実行可能で、API経由でも利用可能 |
Dataset | Apifyで取得したデータの格納庫 |
Hタグ | HTMLの見出しタグ(H1〜H6)。記事の構造を表す重要なSEO要素 |
株式会社TWOSTONE&Sonsグループでは
60,000人を超える
人材にご登録いただいており、
ITコンサルタント、エンジニア、マーケターを中心に幅広いご支援が可能です。
豊富な人材データベースと創業から培ってきた豊富な実績で貴社のIT/DX関連の課題を解決いたします。



幅広い支援が可能ですので、
ぜひお気軽にご相談ください!
-290x163.png)
-290x163.png)